概要
Google Cloud PlatformのBigQueryを用いたデータマート定義の設定のDocsです。
書き込みモードについて
TROCCOでは、SQLと出力先テーブルを指定するだけで、簡単にテーブルへの洗い替えや追記などの操作が可能です。
BigQueryでは、テーブルへの書き込み方法を4つのモードから選択できます。
書き込みモード:全件洗い替え
既存のテーブルのレコードをすべて削除し、クエリ実行結果で置き換える(WRITE_TRUNCATE)モードです。
テーブルの洗い替えを以下の通り行います。
- 一時テーブルを作成して、データを投入する
- 一時テーブルのデータを対象テーブルにWRITE_TRUNCATEする
シンプルな処理のため、データ量が少ない場合や、毎回全件を再計算しても問題ない場合に適しています。
一方で、全データについて処理を実行するため、クエリのスキャン量や処理時間が長くなる傾向があります。
処理時間が長くなったタイミングなどで、他の書き込みモード「増分更新」「SCD Type 2(履歴保持)」などのご利用を検討ください。
書き込みモード:追記
既存のテーブルのレコードの後に、クエリ実行結果が追記(WRITE_APPEND)されます。
「全件洗い替え」とは異なりデータの追記のみ行うため、増分データ(新しいレコード)だけを追加するシンプルな運用に適しています。
既存データとの重複チェックや正確な履歴保持が必要な場合は、他の書き込みモード「増分更新」「SCD Type 2(履歴保持)」のご利用を検討ください。
書き込みモード:増分更新
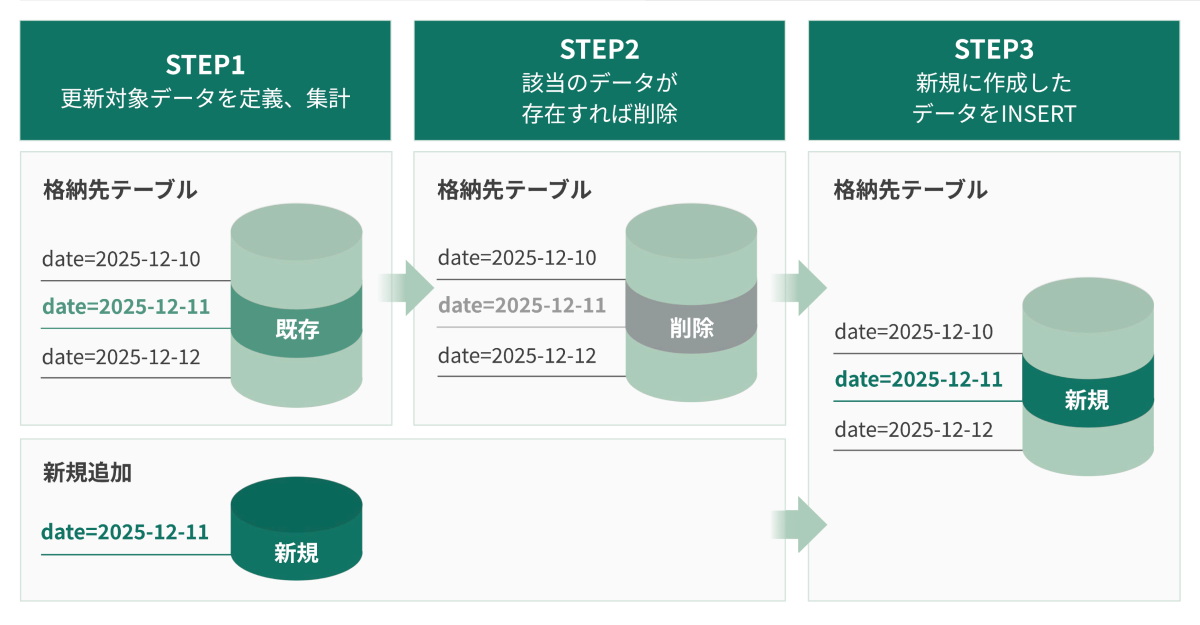
増分更新は、キーカラムに基づく既存のデータが存在した場合にはDELETEしてからINSERTを行う書き込みモードです。
日次・週次のセグメント・ユーザー別売上データなど、時系列ごとの統計値などを格納するテーブルを作成する処理に適しています。
書き込みモード:SCD Type 2(履歴保持)
SCD Type 2(Slowly Changing Dimension Type 2)モードは、履歴を保持しながらディメンションの変更を追跡するモードです。
SCD Type 2(履歴保持)モードを利用することで、利用者や契約者の「住所」や「契約プラン」といった変化する情報について「いつ」「どうであったか」を単一のテーブルに保持できます。
これにより多様な分析要件に柔軟に対応できるほか、過去時点のテーブル(スナップショット)をすべて保持する方法と比較しても、コスト面での優位性を持つテーブル構成となります。

増分更新およびSCD Type 2(履歴保持)は、Essentialプラン以上の契約アカウントでのみ、ご利用いただけます。
BigQuery側で必要な権限
ご利用いただくにあたって必要なBigQuery側の権限は以下となります。
bigquery.datasets.getbigquery.jobs.createbigquery.tables.createbigquery.tables.deletebigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updatebigquery.tables.updateData
STEP1:基本設定
| 項目名 | 必須 | 内容 |
|---|---|---|
| データマート定義名 | ✓ | データマート定義名を入力します。 |
| メモ | - | TROCCO内部で利用するデータマート定義のメモを入力できます。 |
STEP2:データ取得設定
STEP2のデータ取得設定では、主に以下の項目を設定します。
- データ取得設定
- クエリ設定
- 転送オプション設定
- その他データ転送モードに依存する設定
データ取得設定
| 項目名 | 必須 | 内容 |
|---|---|---|
| Google BigQuery接続情報 | ✓ | あらかじめ登録してあるGoogle BigQueryの接続情報から、今回のデータマート定義に必要な権限を持つものを選択します。 |
| クエリ実行モード | ✓ | 以下のいずれかのモードを選択します。
|
| 書き込みモード | ✓ | クエリ実行モードがデータ転送モードの場合に選択できます。以下のいずれかのモードを選択します。
|
クエリ設定
データマートのクエリに関する設定項目です。
データマートのクエリ設定では、レガシーSQLは利用できません。
クエリ編集欄の左下にある クエリを整形をクリックすることで、入力したSQLクエリを自動で整形できます。
整形処理では、キーワードの配置やインデント、改行などが見やすく再配置されます。
データ転送モードの場合
データ取得設定のクエリ実行モードでデータ転送モードを選択した場合の項目です。
| 項目名 | 必須 | 内容 |
|---|---|---|
| 出力先データセット | ✓ | データ出力先のデータセット名を入力します。 データセットの命名規則について、詳しくはBigQuery公式ドキュメント - データセットに名前を付けるを参照ください。 |
| 出力先テーブル | ✓ | データ出力先のテーブル名を入力します。 テーブルの命名規則について、詳しくはBigQuery公式ドキュメント - テーブルの命名を参照ください。 |
| クエリ | ✓ | クエリを入力します。 クエリ内でテーブル名を指定するときは、 dataset_name.table_nameの形式で記述ください。プレビュー実行をクリックすることで、実行結果を確認できます。 |
| スキーマ自動追従モード | ✓ | 書き込みモードが増分更新または**SCD Type 2(履歴保持)**の場合に指定できます。転送先でスキーマ変更があった場合に自動で追従を行うかを設定します。
|
| 転送前に実行するクエリ | - | 書き込みモードが追記の場合のみ指定できます。 データ転送前に実行するクエリを入力します。出力先のテーブルが存在する場合のみ実行されます。 クエリ内でテーブル名を指定するときは、 dataset_name.table_nameの形式で記述ください。 |
| パーティショニング・クラスタリングの設定 | - | パーティショニング・クラスタリングの設定項目です。詳しくはパーティショニング・クラスタリングの設定を参照ください。 |
| テーブル・カラム説明設定 | - | 出力先テーブル・カラムの説明(description)をTROCCOの画面から設定し、ジョブ実行後にBigQueryへ反映できます。詳しくはテーブル・カラム説明設定を参照ください。 |
- 増分更新設定でキーカラムや処理対象期間の基準カラムに利用するカラムを指定したクエリを記載します。
- クエリ設定で入力したクエリは、そのままデータマートジョブでは実行されません。
- 処理対象期間は増分更新設定で行うため、カスタム変数による日時範囲の指定などは不要です。
- 「プレビューを実行」ボタンを押下することで、増分更新設定でキーカラムや基準カラムの設定が可能になります。
- SCD Type 2 設定でキーカラムや増分基準カラム、処理対象期間の基準カラムに利用するカラムを指定したクエリを記載します。
- クエリ設定で入力したクエリは、そのままデータマートジョブでは実行されません。
- 処理対象期間はSCD Type 2 設定で行うため、カスタム変数による日時範囲の指定などは不要です。
- 「プレビューを実行」ボタンを押下することで、SCD Type 2 設定でキーカラムや増分基準カラム、基準カラムの設定が可能になります。
自由記述モードの場合
データ取得設定のクエリ実行モードで自由記述モードを選択した場合の項目です。
| 項目名 | 必須 | 内容 |
|---|---|---|
| クエリ | ✓ | クエリを入力します。 クエリ内でテーブル名を指定するときは、 project_name.dataset_name.table_nameの形式で記述ください。 |
| データ処理ロケーション | - | クエリを実行するGoogle BigQueryのロケーションを指定します。 クエリ内でロケーションに紐付かないリソースを指定する場合はご指定ください。 未指定の場合はGoogle BigQueryによって自動的にロケーションが判別されます。 詳しくは、BigQueryの公式ドキュメント - ロケーションを指定するを参照ください。 |
データ転送モードで利用できる設定
以下のクエリ設定内の設定は、クエリ実行モードがデータ転送モードの場合に利用できます。
スキーマ自動追従モード
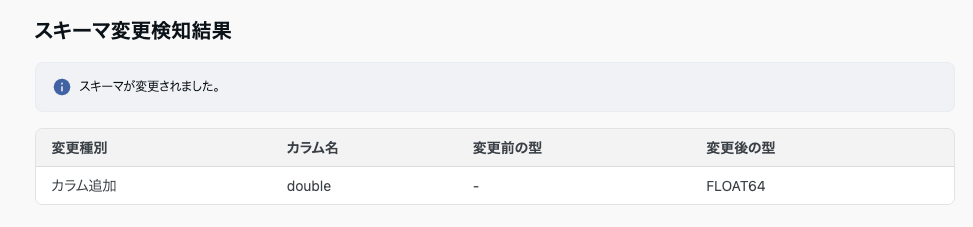
スキーマ自動追従モードとは、データマートジョブの実行時に、クエリのスキーマと出力先テーブルのスキーマを比較し、差分を自動で検知・追従できる機能です。
分析要件の追加などによりテーブルのスキーマが変化した際、TROCCOのデータマート定義のクエリを書き換えるだけで運用を継続できます。
書き込みモードが増分更新または**SCD Type 2(履歴保持)**の場合に表示されます。
検知結果や処理内容は、データマートジョブ詳細画面で確認できます。
カラム自動追加を選択した場合
スキーマ自動追従モードでカラム自動追加を選択した場合、追従対象と動作は以下となります。
| 種別 | 検知対象 | 動作 |
|---|---|---|
| カラム追加 | クエリ結果に存在し、出力先テーブルに存在しないカラム | 出力先テーブルにカラムが自動で追加されます。 |
| カラム削除 | 出力先テーブルに存在し、クエリ結果に存在しないカラム | 自動では行われません。ジョブが失敗します。 |
| 型変更 | 両方に存在するが、データ型が異なるカラム | 自動では行われません。ジョブが失敗します。 |
追従モードがカラム自動追加の場合、カラム削除や型変更が検知されるとジョブが失敗します。
出力先テーブルのスキーマを手動で変更してから、ジョブを再実行してください。
カラム削除および型変更は、誤ったクエリ変更による影響が大きく復旧難易度も高いため、ジョブそのものの失敗として処理されます。
自動追従するのはスキーマのみのため、過去のデータ追加は行われません。必要に応じて過去データを追加してください。
増分更新の場合、該当のデータマートジョブ実行画面から「処理対象期間を上書きする」を有効にすることで、最新のスキーマに基づいて過去の処理対象期間のデータを上書きできます。
検知のみを選択した場合
スキーマ自動追従モードで検知のみを選択した場合、変更の検知のみ行います。
パーティショニング・クラスタリングの設定
パーティショニング・クラスタリングについて、詳しくは分割テーブルの概要・クラスタ化テーブルの概要をそれぞれ参照ください。
パーティショニング・クラスタリングの設定はテーブルの新規作成時にのみ有効です。
出力先に既にテーブルが存在する場合は、本設定の内容ではなく既存テーブルの設定内容でジョブが実行されます。
Google BigQueryの仕様上、パーティションの境界はUTC時間に基づきます。ご注意ください。
| 項目名 | 必須 | 内容 |
|---|---|---|
| パーティショニング | - | 以下のいずれかを選択できます。
|
| パーティションフィールド | ✓ | フィールドにより分割を選択したときに入力します。DATE、TIMESTAMP、DATETIMEのいずれかの型の列名を入力してください。 |
| パーティションタイプ | ✓ | パーティショニングでいずれかの分割方式を選択した場合に選択します。 テーブル分割の粒度を以下より選択してください。
|
| クラスタリング | - | クラスタ化テーブルを作成したい場合に設定できます。 クラスタ化列にカラム名を入力することで、該当のカラムに基づいてテーブルがクラスタ化されます。 なお、クラスタ化列は最大で4つまで指定できます。 |
特定のINTEGER列の値に基づいてテーブルを分割する、整数範囲パーティショニングによるテーブル新規作成には対応していません。
なお、整数範囲パーティショニングによる既存テーブルへの転送は可能です。
テーブル・カラム説明設定
出力先テーブルおよびカラムの説明(description)を、BigQueryコンソールを直接操作することなくTROCCO管理画面から設定できる機能です。
設定した説明は、データマートジョブの実行後にBigQuery側のテーブル・カラムに反映されます。
| 項目名 | 必須 | 内容 |
|---|---|---|
| テーブル説明 | - | 出力先テーブルの説明を入力します。 |
| カラム説明 | - | カラムごとの説明を入力します。 クエリのプレビューを実行するとカラム一覧(カラム名・データ型・説明の入力欄)が表示され、説明を入力できます。 増分更新・SCD Type 2(履歴保持)モードの場合は、各モードの実行クエリプレビューの実行後にカラム一覧が表示されます。 |
テーブル説明・カラム説明は、それぞれ最大1024文字まで入力できます。
また、メタデータを取り込むボタンを押すと、出力先テーブルにBigQuery側ですでに設定されている説明(description)を取得し、フォームへ反映できます。
- Google BigQuery接続情報・出力先データセット・出力先テーブルがすべて入力されている場合に利用できます。
- 取り込みを実行すると、入力中のテーブル・カラム説明が取得した内容で上書きされます。保存する前であれば、画面を再読み込みすることで元に戻せます。
- 取り込んだカラムは、クエリのプレビューを実行していなくても説明の入力欄として表示されます。
設定した説明は、ジョブ実行後にBigQuery側へ次のとおり反映されます。
- 説明を入力したカラム・テーブル:入力した内容がBigQuery側に設定されます。
- 説明を空にしたカラム・テーブル:BigQuery側の説明が削除されます。
- TROCCOの画面で操作していないカラム:BigQuery側で直接設定された説明はそのまま保持され、変更されません。
転送オプション設定
書き込みモードが追記または全件洗い替えの場合に表示されます。
| 項目名 | 必須 | デフォルト値 | 内容 |
|---|---|---|---|
| ジョブの並列実行 | ✓ | 並列でのジョブ実行はしない | ジョブ実行時点で、同一のデータマート定義による他のジョブが実行中の場合に、ジョブを実行するかどうかを選択します。
|
データマートジョブ実行時に発行するクエリの都合上、書き込みモード「増分更新」「SCD Type 2(履歴保持)」ではジョブの並列実行はできません。
増分更新設定
書き込みモードが増分更新の場合に表示されます。
クエリ設定のクエリで取得したカラムを利用して、増分更新のデータ更新方法を定義します。
| 項目名 | 必須 | 内容 |
|---|---|---|
| キーカラム | ✓ | レコードを一意に識別するキーを指定します。複数のカラムを指定できます。 |
| キーが一致するレコードが存在した場合の挙動 | ✓ | キーカラムが一致するレコードが既に存在する場合の処理を選択します。
|
| 処理対象期間 | ✓ | 処理対象とするデータの期間を指定します。
|
設定後、実行されるクエリは「実行クエリプレビュー」より確認できます。
SCD Type 2 設定
書き込みモードが**SCD Type 2(履歴保持)**の場合に表示されます。
クエリ設定に基づいてデータの更新方法を定義します。
| 項目名 | 必須 | 内容 |
|---|---|---|
| キーカラム | ✓ | ビジネスキーとなるカラムを指定します。複数のカラムを指定できます。指定したキーカラムが一致する既存レコードに対して、増分基準カラムの値が更新されている場合は、新しいレコードが作成されます。 |
| 増分基準カラム | ✓ | データの新しさを判定できる「更新日時」や「連番」のカラムを1つ指定します。このカラムに変更があった場合、既存レコードの有効終了日時を更新し、新しいレコードが作成されます。 指定可能なデータ型: DATE、DATETIME、TIMESTAMP、TIME、INT64、INTEGER、NUMERIC、BIGNUMERIC、FLOAT64、FLOAT、DECIMAL |
| 処理対象期間 | ✓ | 処理対象とするデータの期間を指定します。
|
設定後、実行されるクエリは「実行クエリプレビュー」より確認できます。
増分基準カラムの選定に迷われた際は、ソーステーブルに存在する「更新日時」カラムを指定するケースが一般的です。
自動管理カラム
SCD Type 2(履歴保持)モードを使用すると、以下のカラムが出力先テーブルに自動的に追加・管理されます。
| カラム名 | データ型 | 内容 |
|---|---|---|
trocco_valid_from |
TIMESTAMP |
レコードの有効開始時刻。ジョブの実行時刻が入ります。 |
trocco_valid_to |
TIMESTAMP |
レコードの有効終了時刻(NULLは現在有効であることを示します)。nullでない場合は、trocco_is_current が無効にされた時刻が入ります。 |
trocco_is_current |
BOOL |
現行フラグ(TRUEは現在有効なレコードであることを示します。) |
SCD Type 2(履歴保持)モードでは、トランザクション内で以下の処理を行います。
- Step 1:変更があるレコードの既存行をクローズ
trocco_valid_toに現在時刻を設定trocco_is_currentをFALSEに更新
- Step 2:新規レコードまたは変更レコードの新バージョンを挿入
trocco_valid_fromに現在時刻を設定trocco_valid_toにNULLを設定trocco_is_currentをTRUEに設定
SCD Type 2(履歴保持)モードを使用する場合、出力先テーブルには自動管理カラム(trocco_valid_from、trocco_valid_to、trocco_is_current)が必要です。
テーブルが存在しない場合は自動的に作成されます。既存のテーブルを使用する場合は、これらのカラムが存在することを確認してください。
SCD Type 2(履歴保持)モードにて、出力元テーブルからレコードを削除しても、出力先テーブルのレコードは削除されずそのまま残ります。
スキーマ自動追従モードでカラム自動追加を選択した場合でも、自動的に追加される管理カラムは比較対象から除外されます。
STEP3:品質チェック設定
本機能は以下のプランで提供しています。
- Professionalプラン
- Essentialプラン、Advancedプラン(有償オプション)
詳しくは、営業担当者またはカスタマーサクセスまでお問い合わせください。
品質チェック設定が有効にできるのは、クエリ実行モードがデータ転送モードの場合のみです。
自由記述モードでは品質チェック設定は利用できません。
ジョブ実行時に重複する値や不正なNULLのチェックを実施できます。
品質チェックを有効にすると、以下の項目を設定できます。
| 項目名 | 必須 | 内容 |
|---|---|---|
| 単一カラムチェック | ✓(※) | 各カラム単位での品質チェック(一意性チェック・NOT NULLチェック)の対象カラムを選択します。各チェックの仕様については品質チェックできる内容についてを参照ください。 |
| 複合カラム一意性チェック | ✓(※) | 複数カラムの値の組み合わせに重複がないかチェックします。複数の組み合わせを追加できます。各組み合わせでは2つ以上のカラムを指定する必要があります。各チェックの仕様については品質チェックできる内容についてを参照ください。 |
| 失敗時の挙動 | ✓ | 品質チェックで失敗となった場合の挙動を設定します。
|
| 品質チェック対象データ設定 | ✓ | 品質チェックの対象とするデータの範囲を設定します。
|
※ 単一カラムチェックまたは複合カラム一意性チェックのいずれか1つ以上の設定が必須です。
「失敗時の挙動」を「記録のみ」に設定した場合、品質チェックでエラーが検出されてもジョブは成功として扱われます。
品質チェックのエラーを見逃さないために、通知設定にて通知タイプ「ジョブ成功、かつ品質チェックエラー検出時」を設定することをおすすめします。
品質チェックできる内容について
以下のチェック方法をサポートしています。
| 項目名 | 内容 | サポート対象外のデータ型 |
|---|---|---|
| 一意性チェック | 指定カラムの値、もしくはカラムの組み合わせが一意であることを検証できます。 | JSON, GEOGRAPHY |
| NOT NULLチェック | 指定カラムに NULL 値が含まれていないか検証できます。 | ARRAY |
「範囲を指定してチェックする」を有効にしたうえで単一カラムまたは複合カラムに対して一意性チェックを実行した場合、チェックが行われるのは処理対象期間内のみになります。テーブル全体でのチェックが行われるわけではないのでご注意ください。
テーブル全体でのチェックが必要な場合は「全データを対象にチェックする」を選択してください。
処理対象期間の範囲指定について
| 項目名 | 必須 | 内容 |
|---|---|---|
| 基準カラム | ✓ | 範囲指定の基準とするカラムを選択します。DATE・DATETIME・TIMESTAMP型のカラムのみ選択可能です。 |
| 期間 | ✓ | チェック対象とする範囲を指定します。 |
| タイムゾーン | ✓ | 範囲の基準とする現在の日時のタイムゾーンを指定します。基準カラムがDATE・DATETIME型の場合、指定したタイムゾーンで日時が解釈されます。 |