Efficiently update master tables on DWH without duplication
- Print
- PDF
Efficiently update master tables on DWH without duplication
- Print
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
summary
This page introduces how to reflect changes to DWH tables "efficiently" and "without data duplication.
Introduction.
Data Destination Google BigQuery does not have transfer modes such as``UPSERT or``MERGE.
Therefore, the following alternative approaches may be taken, each of which raises its own concerns.
Duplication of data by appending
Instead of UPSERT or``MERGE, there is a way to append ( APPEND or``INSERT) rows that have been changed or added on the data source side.
On the other hand, this method may result in data duplication in the tables on the DWH.
Increased Transfer Time by Full Data Transfer
In order to avoid duplication of data, a method such as " REPLACE" for tables in the DWH can be considered, in which "every time there is a change on the data source side, all cases are rewritten ( REPLACE).
On the other hand, using this method would require retransferring most of the records already in the tables on the DWH, which could result in a huge amount of transfer time.
What we would like to present on this page
We will introduce how to reflect changes to Data Destination BigQuery/Snowflake tables that do not have UPSERT or``MERGE as a transfer mode "efficiently" and "without data duplication" with use cases.
Data Destination Amazon Redshift, Data Destination Snowflake
Data Destination Amazon Redshift and Data Destination Snowflake support UPSERT (MERGE) as the transfer mode.
Please use as appropriate.
use case
Want to avoid data duplication by using unique columns
By using columns with unique values, such as IDs, as merge keys, the master table on the DWH can be updated in a way that eliminates data duplication.
I want it to automatically follow changes on the data source side.
Some Data Source Advertising-based Connectors are designed to generate a preliminary value first, and the value will be finalized at a later date.
By using a workflow that transfers the preliminary data first, and then merges the finalized data with the previously transferred table at a later date, the master table in the DWH can be updated with less man-hours.
I want to reflect large volume data efficiently.
In the case of Data Source DB-based Connector, the data to be transferred may be large.
In this case, by using updated_at columns, etc., only the most recently updated rows can be retrieved and merged into the master table, which is more efficient than Full Load.
update procedures
This is done in three major steps.
The two tables can be transferred to the DWH and merged using a data mart to efficiently update the tables without duplication.
- Creating Master Tables
- Creating Temporary Tables
- Merge temporary tables into master table
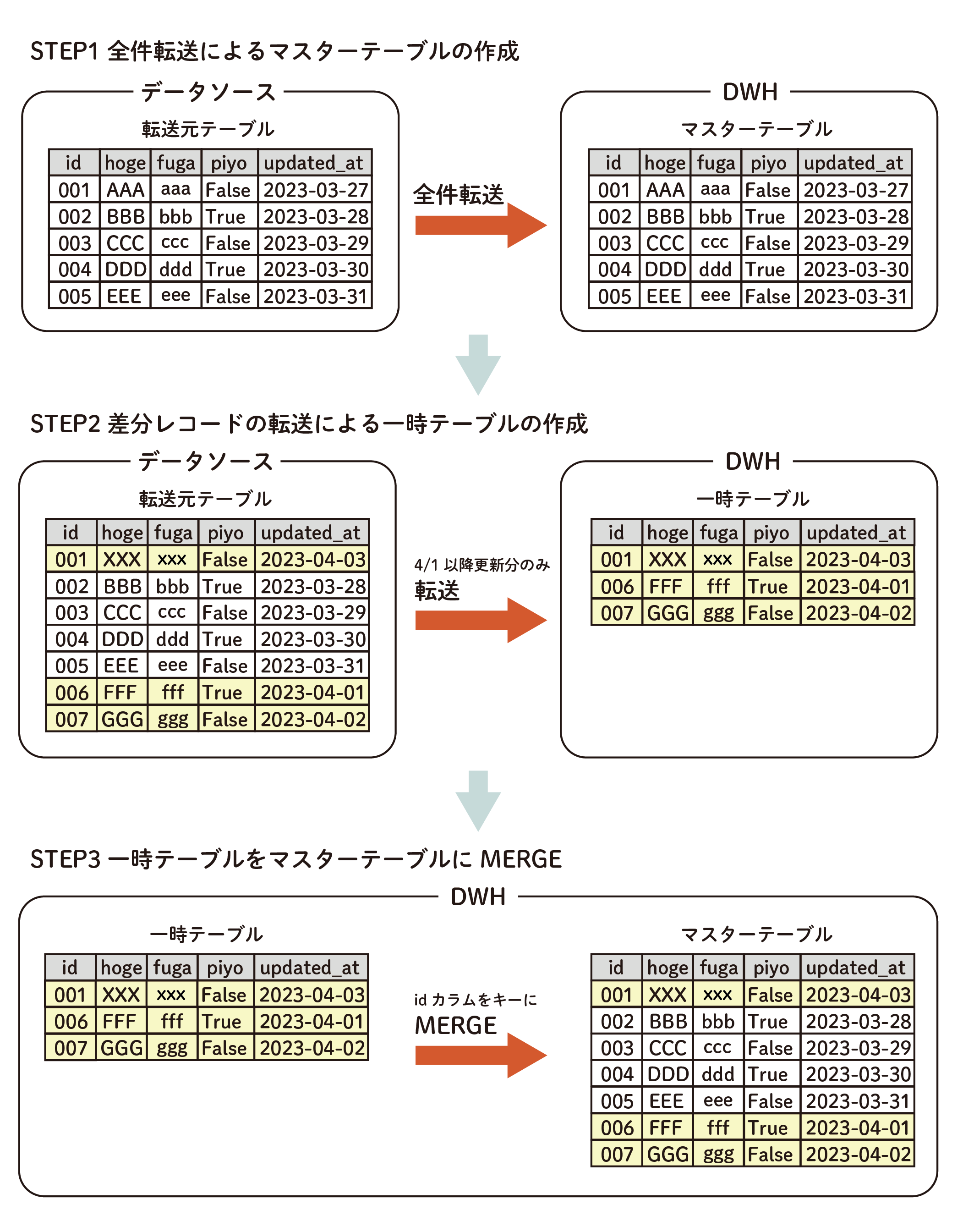
1. create master table
This step is performed only for the first time.
Full Data Transfer to DWH and create a master table.
Create the following ETL Configuration and run the Job
- In the Data Source Configuration, select Full Data Transfer as the ETL Configuration.
- In the Data Source Configuration, write a query for Full Data Transfer.
2. creation of temporary tables
Only Incremental Data Transfer is performed to the DWH to create a temporary table.
Create the following ETL Configuration and run the Job
- In the ETL Configuration on the Data Source side, write a query so that only records that have been updated or added since Step 1 will be transferred.
- Include a WHERE clause such as
WHERE updated_at >= "2023-04-01"
In addition, by embedding Custom Variables for time and date within the WHERE clause, it is possible to operate using the Workflow definition described below.
3. merge temporary tables into the master table
Using a data mart, merge temporary tables into the master table.
Select Free Description mode in the Query Execution Mode of Data Mart Configuration, write a MERGE statement in the query, and execute the job.
Below is a sample query when using the data mart BigQuery.
MERGE
`<master_project>.<master_dataset>.<master_table>` AS master -- master table
USING
`<temp_project>.<temp_dataset>.<temp_table>` AS temp -- temp table
ON
master.id = temp.id
WHEN MATCHED THEN
UPDATE SET
-- Enumerate all columns
master.hoge = temp.hoge,
master.fuga = temp.fuga,
︙
master.piyo = temp.piyo
WHEN NOT MATCHED THEN
-- tips: For BigQuery, write only `INSERT ROW` to insert all columns
INSERT(
-- Enumerate all columns
hoge,
fuga,
︙
piyo
)
VALUES(
-- Enumerate all columns
hoge,
fuga,
︙
piyo
)
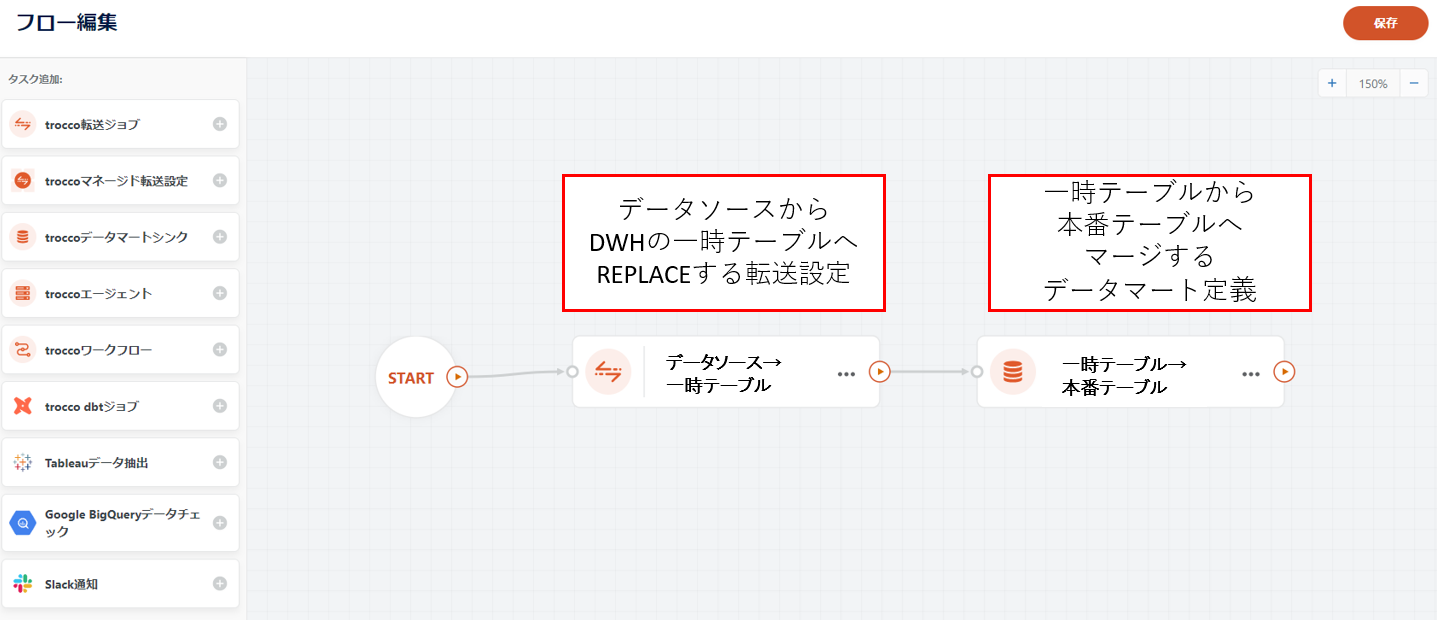
Operation using Workflow definitions
In actual operation, steps 2 and 3 above must be repeated periodically to keep the master table up-to-date.
By creating a Workflow definition that incorporates steps 2 and 3 of the update procedure in sequence for this requirement, it can be operated without spending man-hours.
In addition, the following settings can be used to automate all processes except the initial master table creation in Step 1.
- Embed Custom Variables for the time and date in the WHERE clause of the query described in Step 2.
- Schedule against a Workflow definition
If the MERGE process for a data mart job takes a long time
Another method is to execute queries that contain DELETE and INSERT statements in sequence.
DELETE
`<master_project>.<master_dataset>.<master_table>` AS master -- master table
WHERE
master.id IN (
SELECT id
FROM `<temp_project>.<temp_dataset>.<temp_table>` AS temp -- temp table
)
INSERT
`<master_project>.<master_dataset>.<master_table>` (
-- Enumerate all columns
hoge,
fuga,
︙
piyo
)
SELECT
-- Enumerate all columns
hoge,
fuga,
︙
piyo
FROM
`<temp_project>.<temp_dataset>.<temp_table>` AS temp -- temp table
Was this article helpful?