summary
Schema Tracking is a function that automatically corrects the schema of the Incremental Data Transfer table and resolves the schema difference between the Data Destination and the Connector's table.
Cases where schema differences occur
The following is one typical example of a schema diff.
- Create ETL Configuration
- ETL Job is executed and the table is transferred to Google BigQuery side.
- The schema of the Data Source's data is changed (e.g., columns are added or deleted, column names or types are changed, etc.)
- Edit ETL Configuration and perform Automatic Data Setting when transitioning to STEP2.
-> Column Setting in ETL Configuration STEP2 reflects the schema of the Data Source data.
If Incremental Data Transfer has occurred due to the above example or other reasons, the schema of the table on the Data Destination Connector side must be corrected before the ETL Job is executed again. (*Fixing is not required in some transfer modes.)
However, by using schema tracking, schema differences can be resolved automatically.
Differences detected by schema tracking
The following differences are detected
- Adding columns
- Deleting columns
- Change column type
Target Connector
Schema Tracking is available at the following Data Destination Connectors
- Data Destination Google BigQuery
- Data Destination Snowflake
Data Source Connectors can be used without any special restrictions.
Usage Procedure
In the following, Data Destination Google BigQuery is used as an example.
The assumption is that the procedure starts with "Edit the existing ETL Configuration and the Column Setting in ETL Configuration STEP2 has been changed".
-
Click Save and Apply in ETL Configuration STEP 3.
The following screen will appear
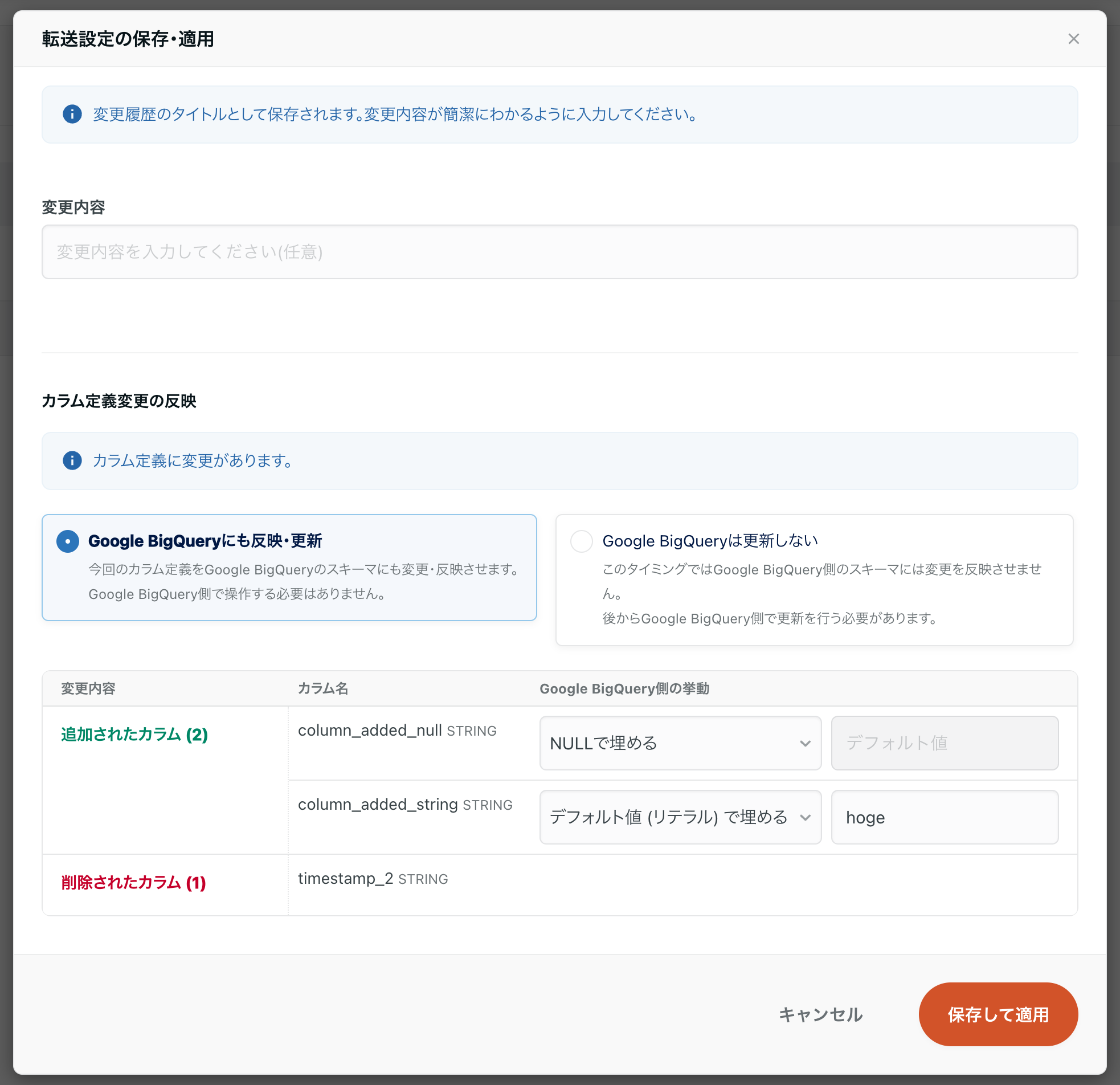
-
Specify the behavior of each column that is subject to change, with BigQuery also selected to reflect and update.
For each added column, you can specify the value to be filled in the existing record from the following
- Fill with NULL
- Fill with default values (literals)
- Fill with literal values (numeric, string,
TRUE/FALSE, etc.)for each type.
- Fill with literal values (numeric, string,
- Fill with default value (expression)
- SQL expressions can be written and filled in.
- You can also use functions such as
CURRENT_TIMESTAMP()or use values from other columns by specifying other column names in the expression.
Note that schema tracking will fail if a value that is not supported by the column type is specified. Please note
- Click Save and Apply.
Takes you to the ETL Configuration details screen. Schema tracking is performed automatically.

ETL Configuration can be re-executed on the ETL Configuration Details screen.
However, schema tracking will not succeed in the cases described in the Usage Restrictions below. Please understand that we are not responsible for any loss or damage to your property.
Usage Restrictions
Restrictions common to each Data Destination Connector
- Schema Tracking cannot be used if Custom Variables are embedded in Table Names, etc. in Data Destination Configuration.
- Columns added, deleted, or changed by the following settings are not subject to schema tracking.
- Transfer Date Column Setting in Transfer Configuration STEP 2
- Programming ETL for ETL Configuration STEP2
- If the schema of a table in the Data Destination Connector is changed directly without going through TROCCO, schema tracking may not work properly.
In schema tracking, if a column name is changed, it is considered "a column is deleted and another column is added.
Therefore, the values contained in the existing columns will be overwritten with the values specified in the modal in ETL Configuration STEP 3. Please note
When schema tracking is performed, the settings that can be configured in TROCCO will be carried over to the tracked table.
For example, the following settings, which can be configured in STEP2>Output Option in the ETL Configuration of Data Destination Google BigQuery, will be inherited.
- Column Description
- Partitioning Table
- Duration of partition
On the other hand, if various settings that cannot be configured in TROCCO are set directly on the Data Destination Connector side, the settings may be lost during schema tracking. Please note
For Data Destination Google BigQuery
- Schema tracking is available only when the following transfer modes are selected
- Postscript
(APPEND) - Postscript
(APPEND DIRECT) - All cases washed
(DELETE IN ADVANCE)
- Postscript
- Schema tracking cannot be used if any of the following apply
- When using a table that refers to the schema information in ETL Configuration STEP2 Output Option****as a template
- If the Data Destination table contains a column of type
RECORD
For Data Destination Snowflake
- Schema tracking is available only when the following transfer modes are selected
- Append
(INSERT) - Postscript
(INSERT DIRECT) UPSERT(MERGE)
- Append
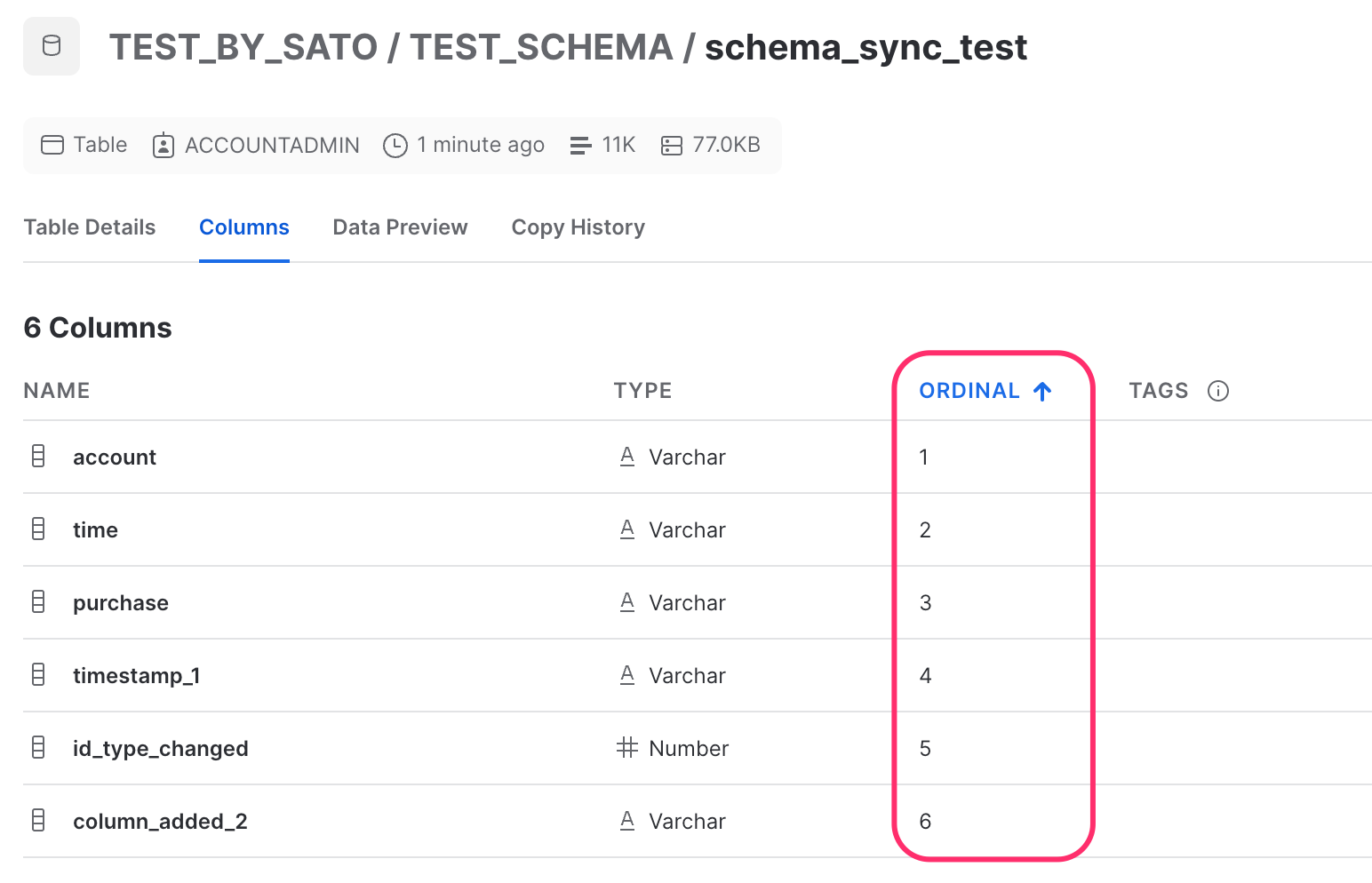
In Data Destination Snowflake, the ETL Job will fail if the column order does not match between the "Table Definition on the Snowflake side" and the "Column Setting in STEP 2 of TROCCO's ETL Configuration".
In addition, any new columns added by schema tracking or columns whose names or column types have been changed will have their ORDINAL order changed to the last column in Snowflake's Table Setting.
Therefore, if an error occurs in the ETL Job after executing schema tracking, please refer to the table definition on the Snowflake side and then replace the order of each column in TROCCO's Column Setting.
supplementary information
- Schema Tracking detects schema incremental data transfers based on the information in ETL Configuration.
- Schema Tracking is available regardless of whether or not features such asColumn Setting Reload andSchema Change Detection are used.
- Schema Tracking does not detect changes in column Descriptions, Output Option changes in ETL Configuration (but not Data Type changes), etc.
- For Data Destination Google BigQuery, when schema tracking is performed, the full amount of SELECT statement queries will be executed. Please be aware that this will require scanning on the Google BigQuery side.