条件分岐タスク
- 印刷
- PDF
条件分岐タスク
- 印刷
- PDF
記事の要約
この要約は役に立ちましたか?
ご意見いただきありがとうございます
概要
条件分岐タスクとは、ワークフローの前段タスクの結果や条件に応じて、実行するタスクを分岐できる機能です。
条件分岐タスクを活用することで、以下のメリットがあります。
柔軟なワークフロー構築
データの状態や処理結果に基づく柔軟なワークフローの構築ができます。
例えば、以下のようなワークフローを構築できます。
- 転送件数を通じてデータマート更新の必要性をチェックし、必要であれば更新するワークフロー
- 転送件数が普段よりも著しく多い場合はSlackにアラート通知をするワークフロー
ジョブ実行の最適化
条件に応じて実行するタスクを分岐できるため、ジョブ実行時間の効率化が可能です。
設定方法
条件分岐のタスクを追加し、名前を設定します。
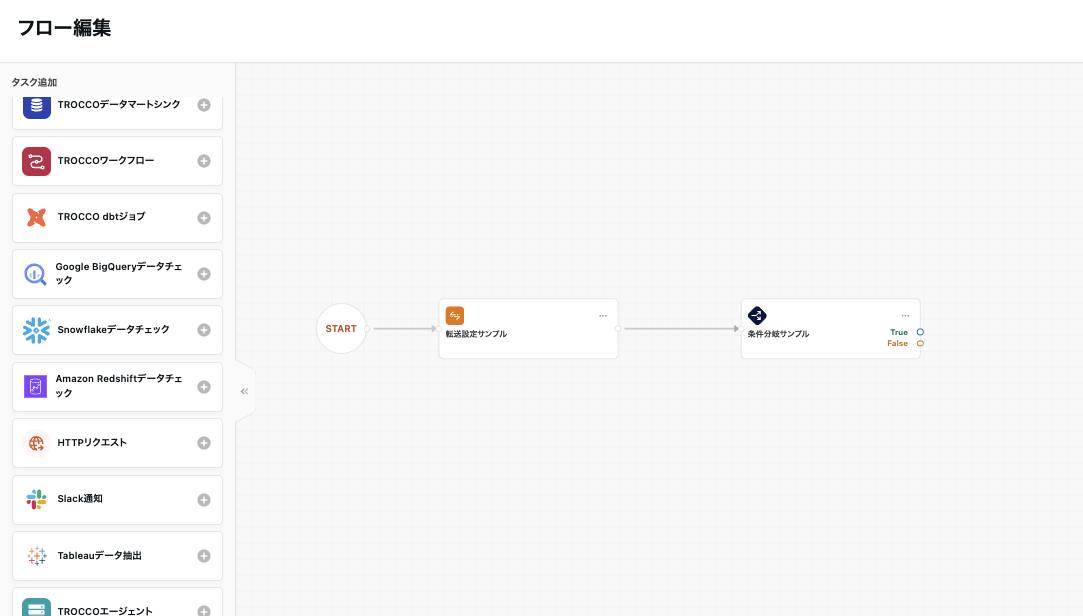
分岐の条件として利用したいタスクを、条件分岐タスクの前段のタスクとしてフローを編集します。
条件分岐タスクを利用する場合のエラーハンドリング
タスクの実行結果エラーを条件に指定して後続のタスクに分岐させるには、ワークフロー全体設定で「タスクのエラーハンドリング」をONにする必要があります。
詳しくはタスクのエラーハンドリングを参照ください。
- 条件分岐タスクの三点リーダーからタスク編集画面を開き、条件式を設定します。
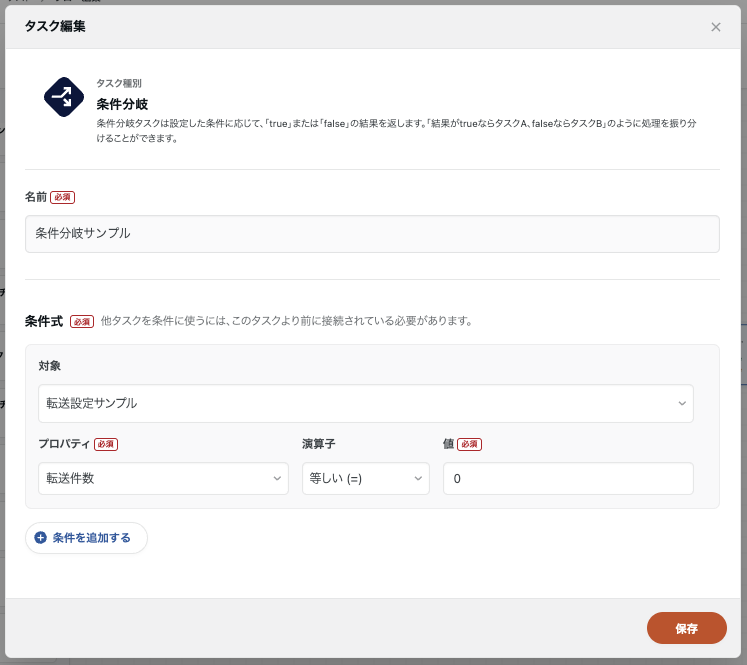
条件式では、以下の項目を対象として利用できます。
- 現在日時
- 条件分岐タスクの実行が開始された日時です
- タイムゾーンまで指定する必要があります。日本時間を指定する場合は末尾に
+09:00を指定してください
- 環境
- ワークフローが実行される環境を条件に設定できます
- 前段のタスクに応じた項目
前段のタスクに応じた項目は、以下のとおりです。
| プロパティ | 値 | 説明 |
|---|---|---|
| ジョブ実行結果 | 成功またはエラー | 前段のタスクのジョブ実行結果に応じて条件を分岐します。 どのタスクが前段でも利用できます。 |
| 転送件数 | 数値 | 前段のタスクで転送されたデータの件数に応じて条件を分岐します。 以下のタスクが前段タスクの際に利用できます。
|
| チェック結果 | チェック成功またはチェック失敗 | データチェックタスクのチェック結果に応じて条件を分岐します。 以下のタスクが前段タスクの際に利用できます。
|
| HTTPステータスコード | 数値 | HTTPリクエストタスクを実行した際のレスポンスのステータスコードに応じて条件を分岐します。 前段のタスクがHTTPリクエストの際に利用できます。 |
条件分岐タスクの前段でデータチェックタスクを実行する場合
データチェックタスクのチェック結果で分岐する場合は、データチェックタスクのエラー条件にて「クエリ結果を条件分岐に利用する」をオンにする必要があります。
設定がオフの場合は、データチェックのエラー条件に合致した時点でワークフローが終了し、条件分岐タスクが実行されません。
カスタム変数ループ実行時の転送件数
前段のタスクがカスタム変数ループ実行の場合は、全ループの合計転送件数が転送件数となります。
また、条件式は複数の対象を組み合わせることも可能です。組み合わせ方法は以下のとおりです。
- AND:すべての条件を満たす
- OR:いずれかの条件を満たす
AND条件とOR条件の組み合わせ
AND条件とOR条件を組み合わせた条件式は設定できません。
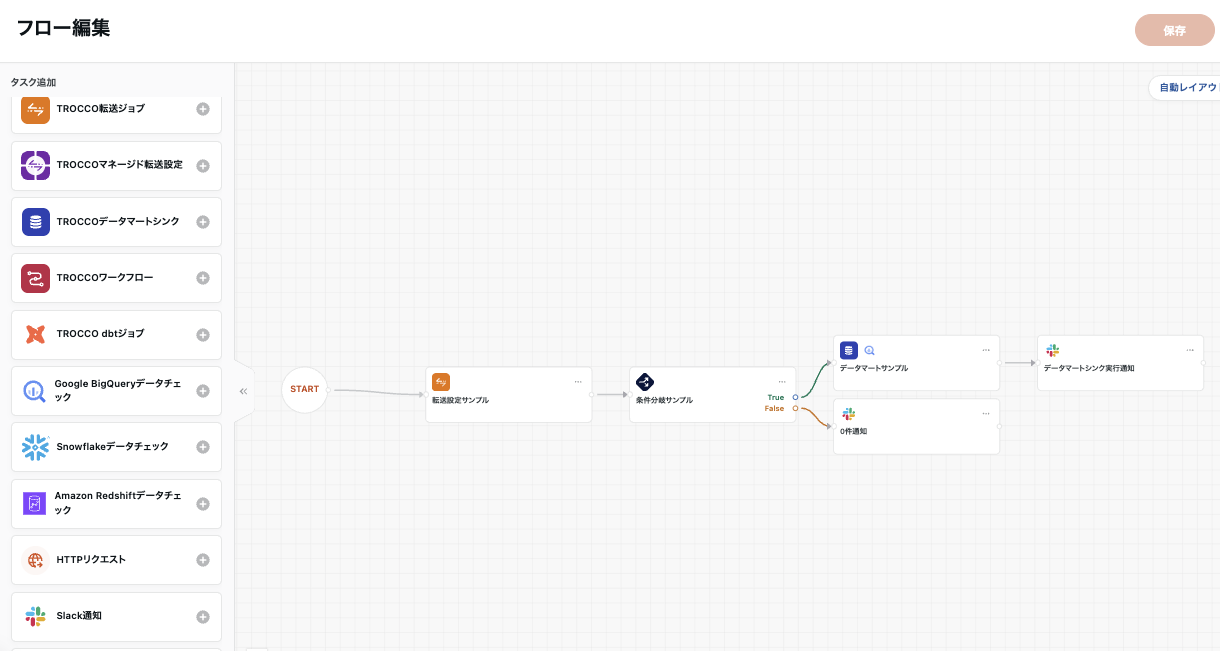
- 条件分岐タスクのTrue側に条件に合致した場合に実行したいタスクを、False側に合致しない場合に実行したいタスクを繋げ、フローを編集します。
ユースケース
条件分岐タスクの代表的なユースケースについてご紹介します。
S3のオブジェクトファイルが更新されていた場合に、データマートタスクを実行する
S3上のオブジェクトファイルが更新されている場合にデータ転送を行い、あわせてデータマートタスクを実行してデータマートも更新するワークフローを構築します。
必要なときだけデータマートを更新するジョブを実行できるため、ジョブ実行時間の効率化が可能となります。
設定例
- 転送設定
- 転送元Amazon S3で、転送方法に「差分転送 (最終更新時間)」を指定します。
- 転送先はデータマートに対応したDWHを指定します。
- データマート定義
- 転送先に指定したDWHのデータマート定義を作成しておきます。
- ワークフロー定義
- TROCCO転送ジョブ → 条件分岐 となるようフローを編集します。
- 条件分岐タスクの条件式を以下のように設定します。
- プロパティ:
転送件数 - 演算子:
より大きい (>) - 値:
0
- プロパティ:
True側にTROCCOデータマートシンクのタスクを、False側は後続タスクを配置せず、対象ファイルなしとしてワークフロー実行が終了されるようフローを編集します。- スケジュールを設定し、定期的にワークフローを実行します。
BigQueryのデータをチェックし、データの正誤によって処理を変える
Google BigQueryデータチェックを利用して転送したデータをチェックし、意図しないデータが入った場合はSlack通知をするワークフローを構築します。
設定例
- ワークフロー定義
- Google BigQueryデータチェック → 条件分岐 となるようフローを編集します。
- データチェックタスクに、エラーを検知するSQLやエラー条件を設定しておきます。
- 例:特定カラムにNULLを含むデータがないかチェックしたい場合
- SQL
SELECT count(id) FROM dataset_name.table_name WHERE subject IS NULL - エラー条件
- クエリ結果:
1 - 条件:
以上 - 「クエリ結果を条件分岐に利用する」をオン
- クエリ結果:
- SQL
- 条件分岐タスクの条件式を以下のように設定します。
- プロパティ:
チェック結果 - 演算子:
等しい (=) - 値:
チェック成功
- プロパティ:
True側にはそのまま後続タスクを、False側はSlack通知を後続タスクとしてフローを編集します。- 必要に応じてスケジュールなどを設定します。
- 例:特定カラムにNULLを含むデータがないかチェックしたい場合
この記事は役に立ちましたか?