DWH의 마스터 테이블을 중복 없이 효율적으로 업데이트하는 방법
- 인쇄
- PDF
DWH의 마스터 테이블을 중복 없이 효율적으로 업데이트하는 방법
- 인쇄
- PDF
기사 요약
이 요약이 도움이 되었나요?
의견을 보내 주셔서 감사합니다.
개요
이 페이지에서는 DWH의 테이블에 대해 '데이터 중복 없이' '효율적으로' 변경 사항을 반영하는 방법을 소개합니다.
소개
전송 대상인 Google BigQuery에는 UPSERT, MERGE와 같은 적재 모드가 없습니다.
이에 대한 대안으로 다음과 같은 방법으로 대응할 수 있지만, 각각 우려되는 점이 있습니다.
추가에 의한 데이터 중복
UPSERT나``MERGE 대신 데이터 소스 측에서 변경/추가된 행을 추가( APPEND나``INSERT )하는 방법이 있다.
한편, 이 방법을 사용하면 DWH의 테이블에서 데이터 중복이 발생할 수 있습니다.
전체 교체로 전송 시간 증가
데이터 중복을 피하기 위해 DWH의 테이블에 대해 '데이터 소스 측의 변경이 있을 때마다 전체 교체( REPLACE )를 수행하는' 방법도 생각해 볼 수 있다.
한편, 이 방법을 사용하면 이미 DWH에 있는 테이블에 있는 대부분의 레코드를 다시 전송해야 하므로 전송 시간이 엄청나게 길어질 수 있습니다.
이 페이지에서 소개하고 싶은 것들
적재 모드로 UPSERT나``MERGE가 없는 전송 대상 BigQuery, Snowflake의 테이블에 대해 '데이터 중복 없이' '효율적으로' 변경 사항을 반영하는 방법을 사용 사례와 함께 소개합니다.
타겟 Amazon Redshift, 타겟 Snowflake
타겟 Amazon Redshift와 타겟 Snowflake는 적재 모드로 UPSERT(MERGE) 를 지원합니다.
적절히 이용하시기 바랍니다.
사용 사례
고유 컬럼을 이용하여 데이터 중복을 피하고 싶다.
ID와 같은 고유한 값을 가진 컬럼을 매칭 키로 활용하여 DWH의 마스터 테이블을 데이터 중복을 제거하는 형태로 업데이트할 수 있다.
데이터 소스 측의 변경 사항을 자동으로 추적하고 싶다
소스 광고계 커넥터 중에는 속보값이 먼저 생성되고 나중에 값이 확정되는 사양의 커넥터가 있습니다.
먼저 잠정값을 전송하고 나중에 확정된 값을 먼저 전송한 테이블에 병합하는 워크플로우를 구성하여 DWH의 마스터 테이블을 인력을 들이지 않고도 업데이트할 수 있습니다.
대용량 데이터를 효율적으로 반영하고 싶다
소스 DB 계열 커넥터의 경우, 전송 대상 데이터가 대용량인 경우가 있습니다.
이 경우 updated_at 컬럼 등을 이용하여 가장 최근에 갱신된 행만 가져와 마스터 테이블에 대해 병합하면 전체 건을 새로 고치는 것에 비해 효율적으로 DWH의 마스터 테이블을 갱신할 수 있습니다.
업데이트 절차
크게 3단계로 진행됩니다.
두 테이블을 DWH로 전송하고 데이터 마트를 이용해 병합하면 중복 없이 효율적으로 테이블을 업데이트할 수 있습니다.
- 마스터 테이블 생성
- 임시 테이블 생성
- 임시 테이블을 마스터 테이블로 병합
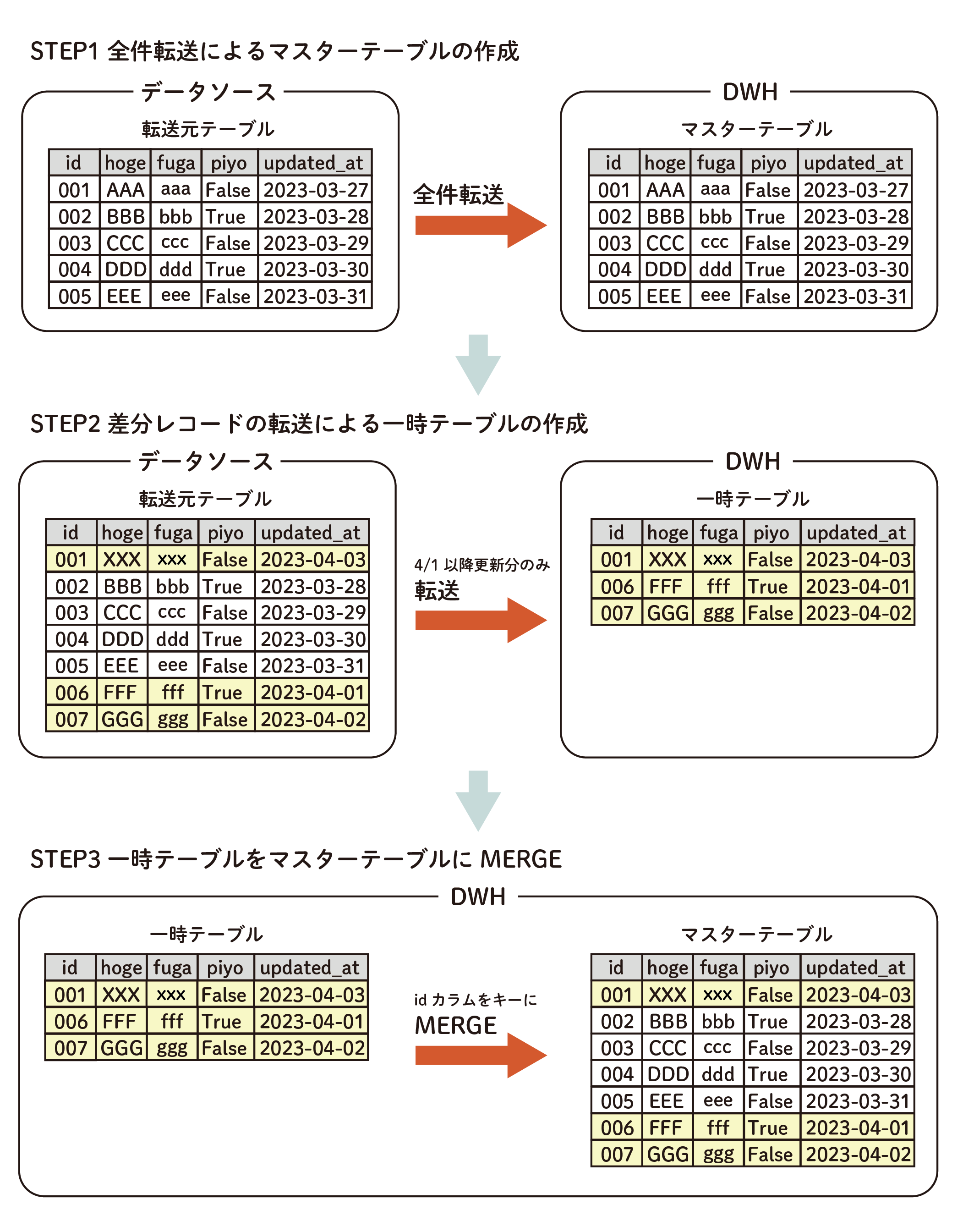
1. 마스터 테이블 생성
이 단계는 최초 1회만 진행합니다.
DWH에 대해 모든 건을 전송하여 마스터 테이블을 생성합니다.
아래와 같이 전송 설정을 생성하고 작업을 실행합니다.
- 소스 측 설정에서 전송 설정으로 전체 전송 을 선택합니다.
- 소스 측 설정에서 모든 건을 전송하도록 쿼리를 작성합니다.
2. 임시 테이블 만들기
DWH에 대해 차분 레코드만 전송하여 임시 테이블을 생성합니다.
아래와 같이 전송 설정을 생성하고 작업을 실행합니다.
- 소스 측 설정에서 1단계 실행 후 업데이트/추가된 레코드만 전송되도록 쿼리를 작성한다.
- 다음과 같은 WHERE 문구를 포함한다.
WHERE updated_at >= "2023-04-01"
또한, WHERE 구문 내에 시간 및 날짜의 커스텀 변수를 삽입하여 후술할 워크플로우 정의에 따라 운영할 수 있습니다.
3. 임시 테이블을 마스터 테이블로 병합
데이터 마트를 사용하여 임시 테이블을 마스터 테이블에 병합합니다.
데이터마트 정의의 쿼리 실행 모드에서 자유 기술 모드를 선택하고 MERGE 문장을 쿼리에 기술하고 작업을 실행합니다.
다음은 데이터마트 BigQuery를 사용할 때의 쿼리 예시입니다.
MERGE
`<master_project>. <master_dataset>. <master_table>` AS master -- master table
USING
`<temp_project>. <temp_dataset>. <temp_table>` AS temp -- temp table
ON
master.id = temp.id
WHEN MATCHED THEN
업데이트 세트
-- 모든 열 열거
master.hoge = temp.hoge,
master.fuga = temp.fuga,
︙
master.piyo = temp.piyo
WHEN NOT MATCHED THEN
-- tips: BigQuery의 경우 모든 열을 삽입하려면 `INSERT ROW`만 작성합니다.
INSERT(
-- 모든 열 열거
hoge,
fuga, fuga
︙
piyo
)
VALUES(
-- 모든 열 열거
hoge,
fuga, fuga
︙
piyo
)
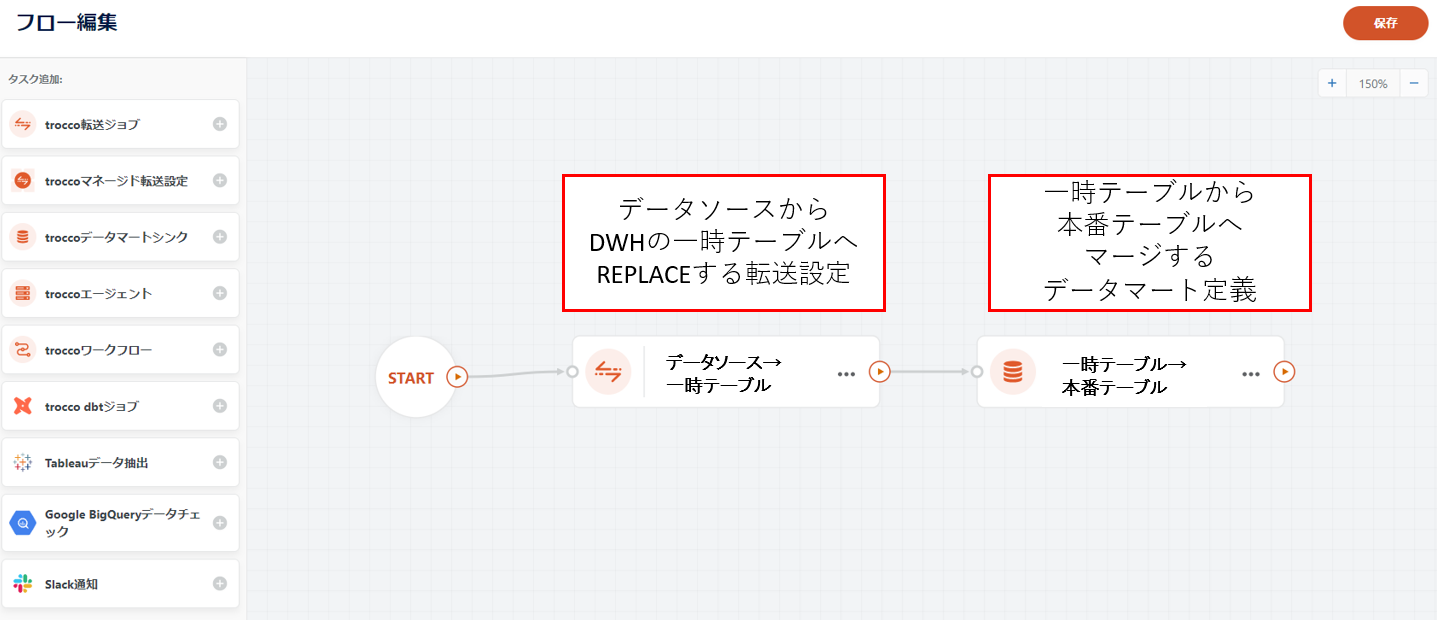
워크플로우 정의를 이용한 운영
실제 운영에서는 위의 2, 3단계를 주기적으로 반복하여 마스터 테이블을 항상 최신 상태로 유지해야 합니다.
이 요구사항에 대해 업데이트 절차의 2단계와 3단계를 순서대로 통합한 워크플로우 정의서를 작성하여 인력을 투입하지 않고도 운영할 수 있습니다.
또한, 아래의 설정을 통해 1단계의 최초 마스터 테이블 생성 외의 모든 과정을 자동화할 수 있습니다.
- 2단계에서 작성한 쿼리의 WHERE 구문에 시간/일시 사용자 지정 변수를 삽입합니다.
- 워크플로우 정의에 대한 스케줄 설정하기
데이터마트 작업의 MERGE 처리에 시간이 오래 걸리는 경우
DELETE 문과 INSERT 문이 포함된 쿼리를 순서대로 실행하는 방법도 있습니다.
DELETE
`<master_project>. <master_dataset>. <master_table>` AS master -- master table
WHERE
master.id IN (
SELECT id
FROM `<temp_project>. <temp_dataset>. <temp_table>` AS temp -- temp table
)
INSERT
`<master_project>. <master_dataset>. <master_table>` (
-- 모든 열 열거
hoge,
fuga, fuga
︙
piyo
)
SELECT
-- 모든 열 열거
hoge,
fuga, fuga
︙
piyo
FROM
`<temp_project>. <temp_dataset>. <temp_table>` AS temp -- temp table
이 문서가 도움이 되었습니까?