개요
MySQL의 binlog에서 CDC(Change Data Capture) 방식으로 변경된 데이터만 식별하여 BigQuery로 전송할 수 있습니다.
이를 통해 전송량을 줄이고 전송 속도를 높일 수 있습니다.
처음 실행할 때 모든 건을 전송해야 합니다. 이후 전송 시에는 차액만 CDC 방식으로 연동합니다.
필수 조건
MySQL 대응표
| Master | Read Replica | 지원 버전 | |
|---|---|---|---|
| Amazon Aurora MySQL RDS | ○ | x | 5.6.2+ |
| Amazon MySQL RDS | ○ | ○ | 5.6.2+ |
| Google CloudSQL MySQL | ○ | x | 5.6.2+ |
| MariaDB | ○ | ○ | 5.6.2+ |
| MySQL | ○ | ○ | 5.6.2+ |
MySQL 매개변수 설정
[mysqld]
binlog_format=ROW
binlog_row_image=FULL
expire_logs_days=7
binlog_expire_logs_seconds=604800
log_bin=mysql-binlog
log_slave_updates=1
보충 설명은 다음과 같습니다.
* binlog 설정을 반영하기 위해 DB 재부팅이 필요할 수 있습니다.
* 컬럼: binlog_expire_logs_seconds
MySQL 8.0.1 이상은 지정해 주세요.
7일로 지정되어 있지만, 더 짧게 지정할 수도 있습니다.
매번 전송하는 빈도보다 충분히 길어야 합니다.
* 컬럼: expire_logs_days
MySQL 8.0.0 이하인 경우 설정해 주세요.
7일로 지정되어 있지만, 더 짧게 지정할 수도 있습니다.
매번 전송하는 빈도보다 충분히 길어야 합니다.
* 컬럼: log_bin
자유롭게 변경하셔도 괜찮습니다.
* 컬럼: log_slave_updates
Read Replica에서 binlog를 가져올 때 설정해 주세요.
- RDS MySQL
expire_logs_days는``mysql.rds_set_configuration프로시저를 사용하여 설정한다.
참고 : https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_LogAccess.Concepts.MySQL.html - Cloud SQL
point-in-time recovery를활성화하십시오.
참고 : https://cloud.google.com/sql/docs/mysql/backup-recovery/backups?authuser=2#tips-pitr
연결 사용자 권한
아래 3가지 권한이 필요합니다.
SELECT
- 데이터 수집
- 테이블 스키마 정보 참조
예: 예시
GRANT SELECT ON `<database_name>`. `<table_name>` to `<사용자명>``@'%'`;
REPLICATION CLIENT, REPLICATION SLAVE
예: 예시
GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *. * TO `<사용자 이름>`@'%';.
소스 테이블의 Primary Key
전송 원본 테이블에는 Primary Key 설정이 필요합니다.
여러 개의 Primary Key(Composite Primary Key)도 지원합니다.
전송 시 변환 기능
MySQL to BigQuery의 CDC 전송은 다음을 지원합니다.
* 컬럼 드롭
* 컬럼 데이터 변환
* 컬럼 이름 변경
컬럼의 데이터 변환은 BigQuery에서 CAST로 이루어집니다. 그래서 BigQuery의 CAST 규칙을 따릅니다.
자세한 내용은 아래를 참고하세요.
https://cloud.google.com/bigquery/docs/reference/standard-sql/conversion_rules?hl=ja
메타데이터
trocco_fetched_at라는 컬럼이 추가되어 DWH와 연동됩니다.
이 컬럼은 TROCCO의 전송 작업에 의해 전송이 시작된 시간을 값으로 가지고 있습니다.
본 컬럼이 추가되는 관계로 _trocco_fetched_at라는 문자열을 컬럼 이름으로 사용할 수 없습니다.
소스 MySQL의 SQL 대응
- INSERT
- 업데이트
- DELETE
- 삭제된 데이터는 DWH 측에서 논리적으로 삭제됩니다.
제한이 있는 SQL
ALTER TABLE ... RENAME COLUMN old_col_name TO new_col_name
스키마 추적을 활성화한 경우, 변경된 이름으로 데이터 연동이 이루어집니다.
이미 연동된 컬럼은 삭제되지 않고 값이 NULL로 설정됩니다.ALTER TABLE ... ADD col_name date_type
스키마 추적을 활성화한 경우에만 자동으로 전송됩니다.
컬럼을 추가할 때는 관리 화면에서 설정한 후 MySQL 컬럼을 추가해야 합니다.
컬럼 추가 후 이미 연동되어 있는 경우 데이터 누락이 발생할 수 있습니다.ALTER TABLE ... DROP col_name
DWH에 연동된 데이터는 삭제되지 않으며, 삭제 이후에는 NULL이 입력됩니다.ALTER TABLE ... MODIFY col_name column_definition
변경된 금형이 금형 변경이 가능하다면 계속 전송할 수 있습니다.
오류가 발생한 경우 모든 건을 전송해야 합니다.
지원되지 않는 SQL
아래 SQL은 binlog에서 캐치할 수 없기 때문에 데이터가 DWH로 제대로 전송되지 않습니다.
- TRUNCATE
- DROP
- LOAD
- RENAME
- CASCADING DELETES
- 캐스케이드 업데이트
- ALTER TABLE ... SET DEFAULT
이미 연동되어 있는 데이터가 NULL인 경우 NULL인 상태로 업데이트되지 않습니다.
MySQL과 BigQuery의 스키마 유형
데이터 타입 변환 기능에서 변경이 가능한 데이터 타입은 지정한 타입으로 변환할 수 있습니다.
기본적으로 아래와 같이 대응하고 있습니다. 바이너리 데이터는 16진수로 변환되어 STRING으로 처리됩니다.
| MySQL 데이터 유형 | BigQuery 데이터 유형 |
|---|---|
| BINARY BLOB LONGBLOB MEDIUMBLOB TINYBLOB VARBINARY CHAR ENUM LONGTEXT MEDIUMTEXT SET TIME TINYTEXT VARCHAR |
STRING |
| BIT TINYINT |
BOOLEAN |
| BIGINT INT MEDIUMINT SMALLINT YEAR |
INTEGER |
| DECIMAL NUMERIC DOUBLE FLOAT |
FLOAT |
| DATE | DATE |
| TIMESTAMP DATETIME |
TIMESTAMP |
| GEOMETRY GEOMETRYCOLLECTION JSON LINESTRING MULTILINESTRING MULTIPOINT MULTIPOLYGON POINT POLYGON |
STRING (STRUCT는 현재 지원하지 않습니다.) |
| CURVE MULTICURVE MULTISURFACE |
SURFACE 지원하지 않습니다. |
설정의 흐름
1. 전송 설정 생성
전송할 MySQL binlog, 전송할 BigQuery를 선택하고 전송 설정을 생성합니다.

STEP2 데이터 미리보기 및 상세 설정에서 'BigQuery 컬럼 설정 저장'을 반드시 눌러 설정을 저장해야 합니다.
2. 첫 번째 전체 전송
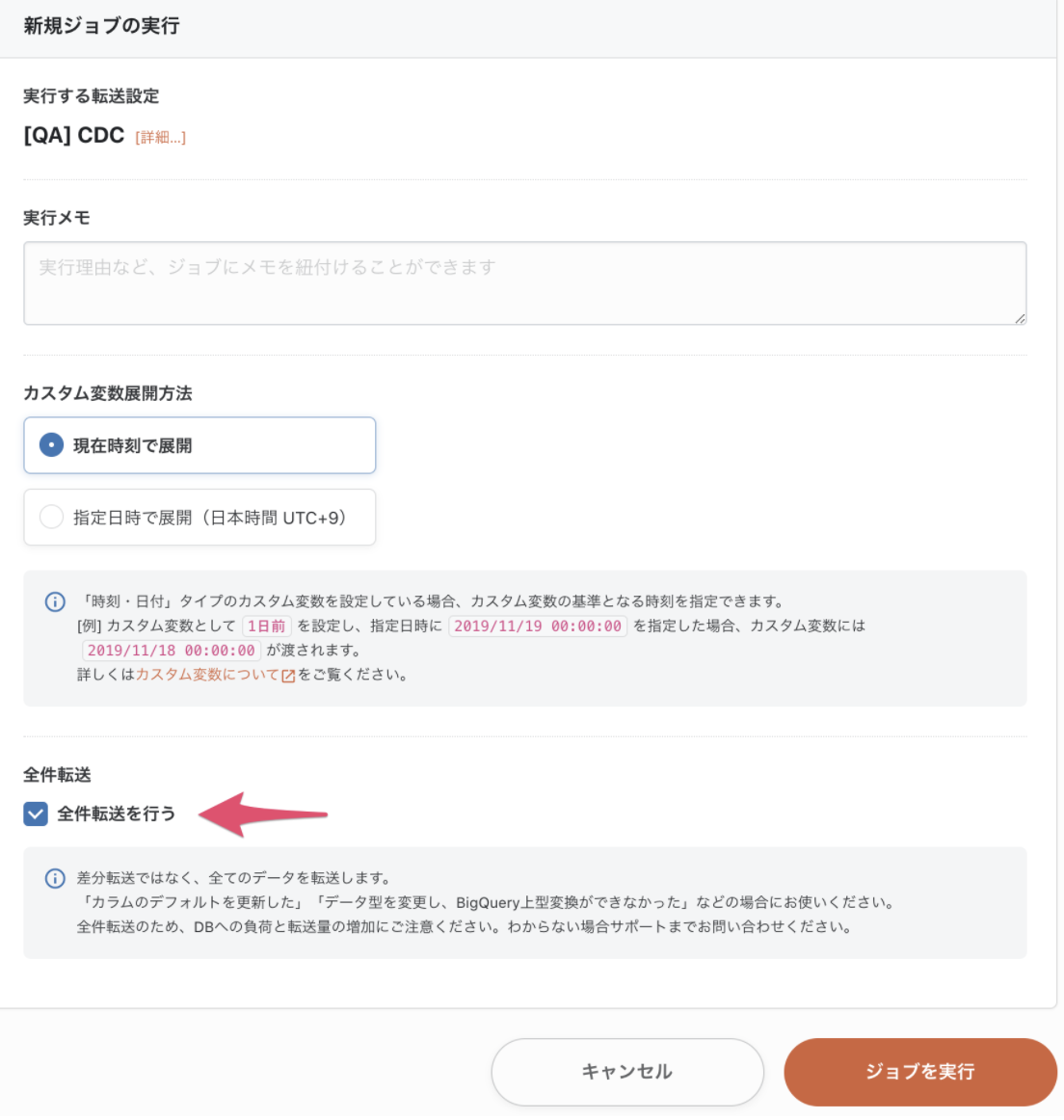
최초 1회만 전체 전송을 수행하여 현재 MySQL의 테이블을 모두 BigQuery로 전송합니다.
신규 작업 실행 화면에서****전체 전송을 체크하고 작업을 실행합니다.
3. 차등 전송 스케줄 설정
스케줄 설정 화면에서 스케줄을 등록해 주세요.
설정한 빈도로 작업이 시작되고 차분한 작업이 실행됩니다.
전체 전송이 필요한 경우
다음과 같은 경우 전체 전송이 필요합니다.
- 첫 번째 전송
- BigQuery에서 타입 변환 런타임 오류가 발생합니다.
- 논리적 삭제가 아닌 모든 데이터를 지우고 싶다.
전송 중인 테이블을 삭제한 후 실행하십시오. - '타겟 MySQL의 SQL 대응'에서 설명한 쿼리를 실행하는 경우
테크니컬 오버뷰
CDC의 기술적 개요
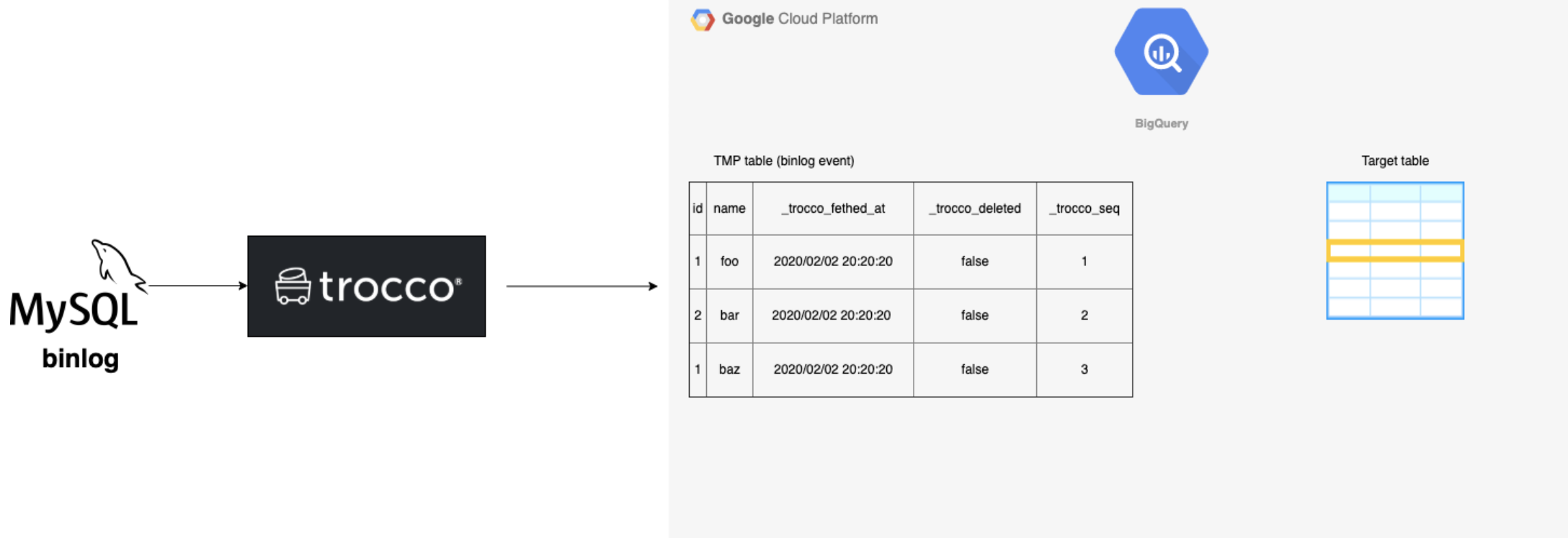
target table : 최종적으로 데이터를 담을 테이블
1. TROCCO가 MySQL의 binlog를 읽어와서 설정된 테이블의 binlog를 BQ로 전송합니다.
-
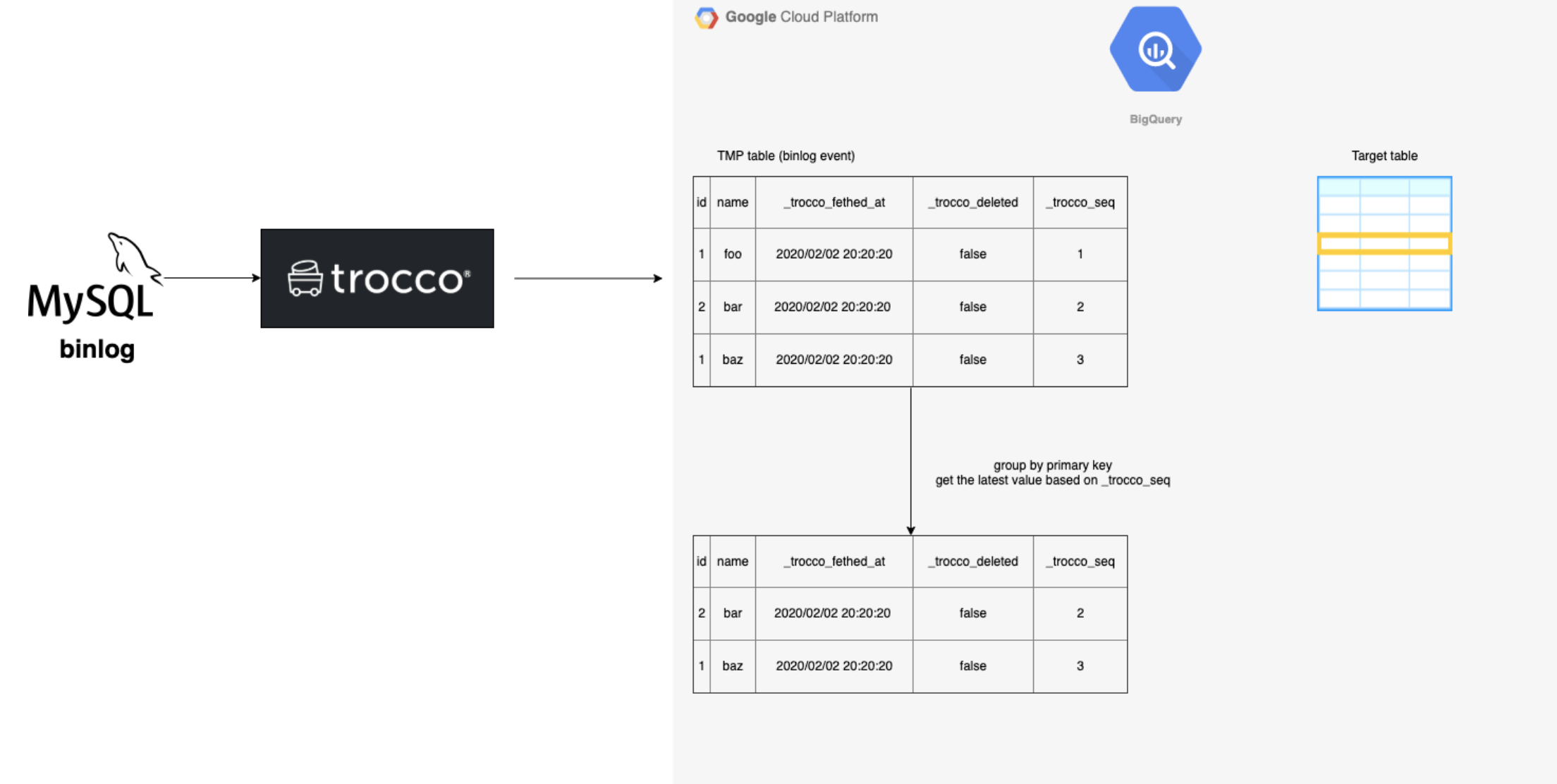
binlog의 데이터는 중복이 있기 때문에 각 레코드의 최신 레코드 집합을 생성합니다.
-
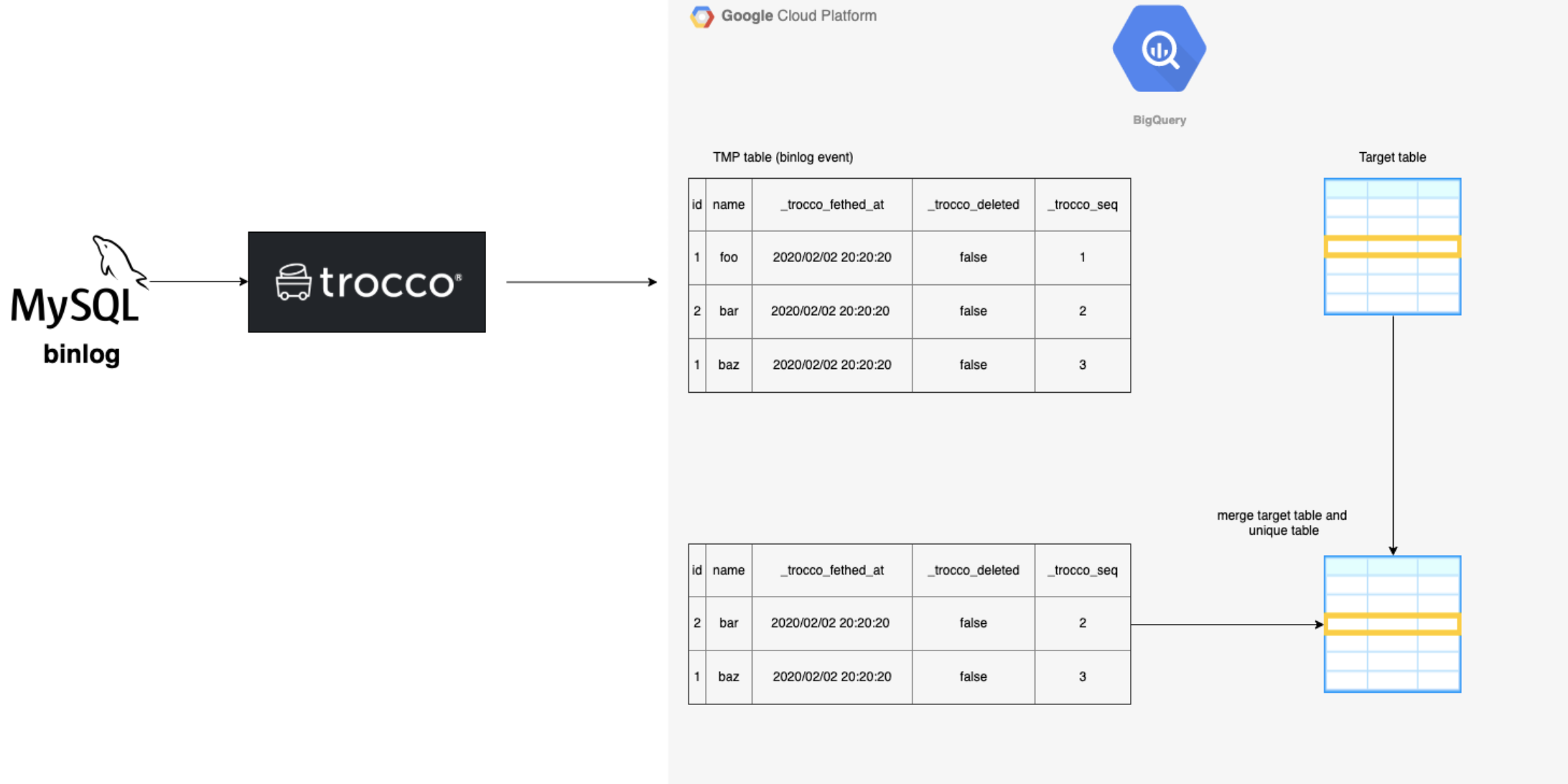
2에서 만든 테이블과 이미 연동된 테이블을 병합합니다.
-
3에서 병합한 테이블을 target table으로 대체합니다.
