2022年10月のリリース情報をお届けします
データカタログ
メタデータCSVインポートに対応🎉
基本メタデータの値を、CSVファイルを用いてインポートできるようになりました🎉
以下では、簡単にインポート手順をご紹介します。
CSVファイルのフォーマットや利用上の制約など、詳しくはメタデータインポートを参照ください。
-
フォーマットに沿ったCSVファイルを用意します。
-
データカタログ設定>メタデータインポートを順にクリックします。
-
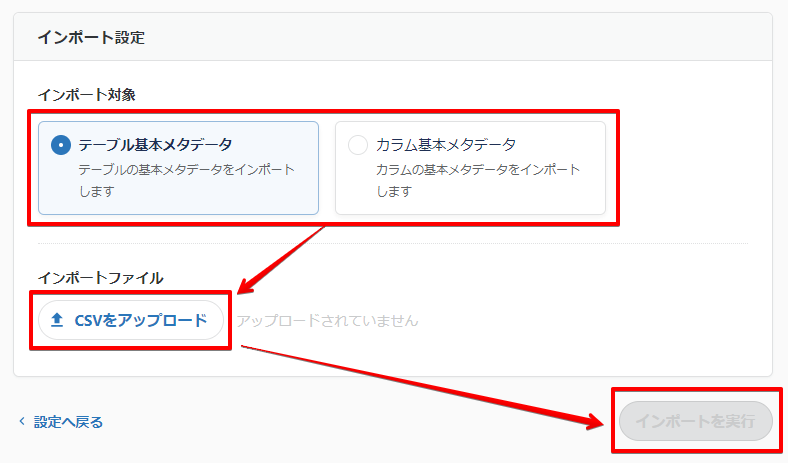
インポート対象を選択し、CSVファイルをアップロード・インポートを実行します。
-
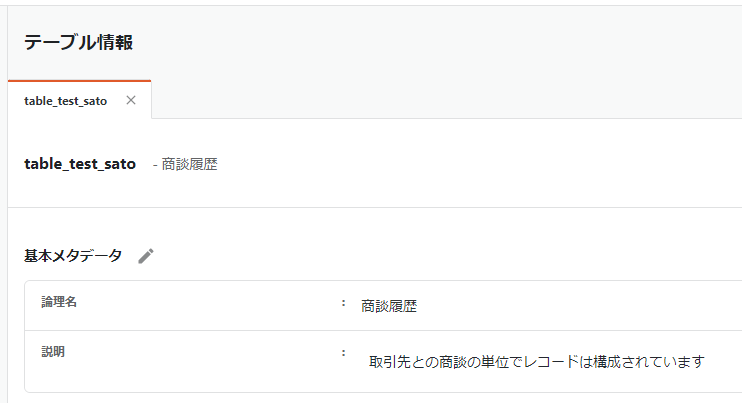
インポートに成功すると、以下のように基本メタデータの値が上書きされます。
要約統計情報表示の強化
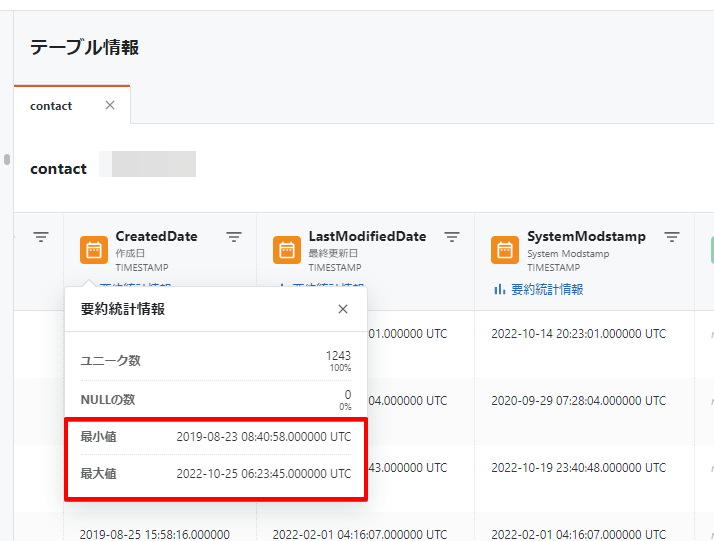
日付・時刻に関する型の最小値・最大値を表示するようになりました。
なお、要約統計情報は、テーブル情報の「カラム情報」や「プレビュー」などで確認できます。
接続情報
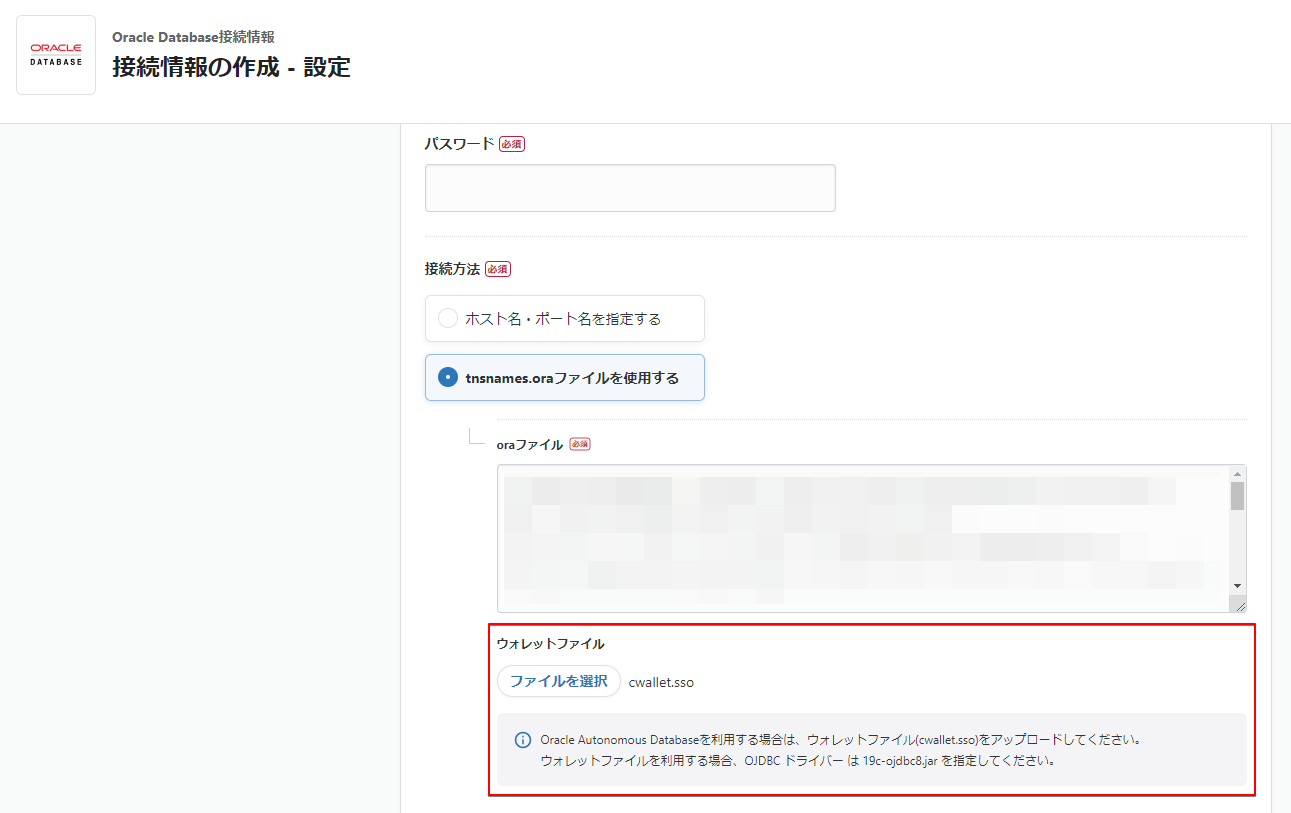
Oracle Autonomous Databaseへの接続に対応
Oracle Database接続情報の「接続方法」にて、tnsnames.oraファイルを使用するを選択したときに、ウォレットファイルをアップロードできるようになりました。
ウォレットファイルをアップロードすることで、Oracle Autonomous Databaseへの接続が可能となります。
転送設定
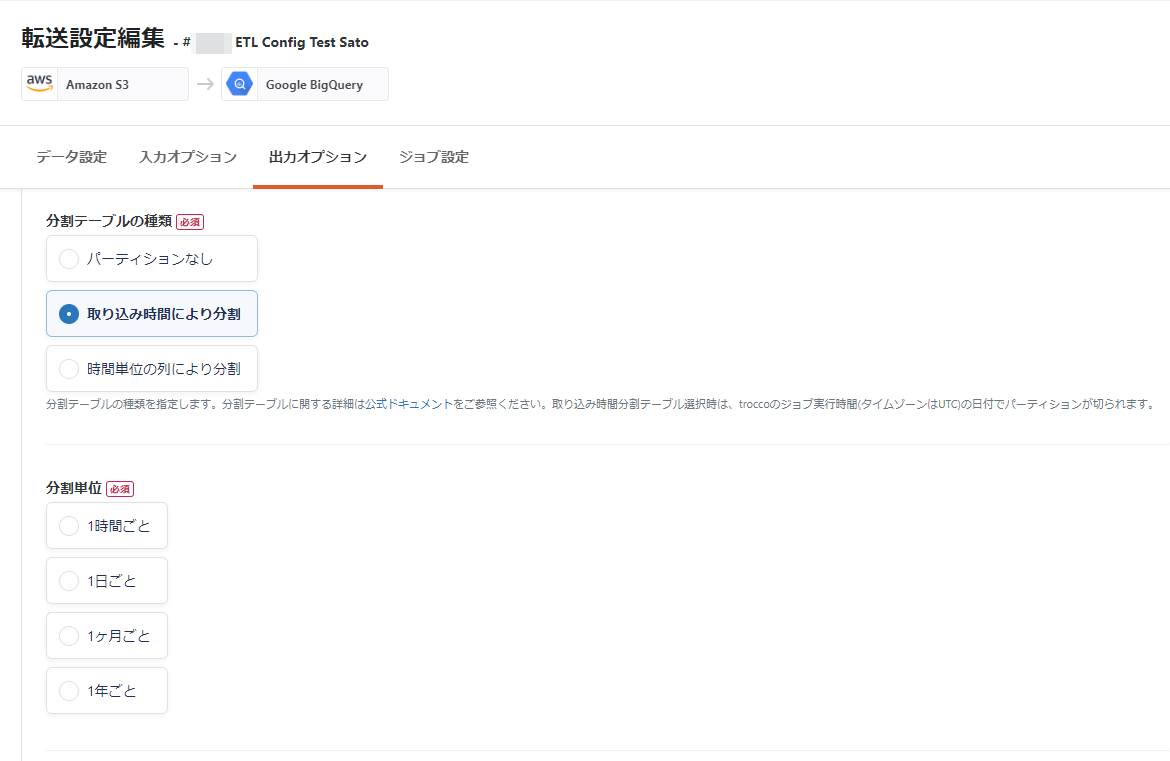
転送先BigQuery テーブル分割パーティション機能の強化🎉
転送先Google BigQueryの転送設定STEP2「出力オプション」にて、テーブル分割パーティションの基準となる時間単位をより細かく設定できるようになりました。
- 今回の変更で、テーブル分割の時間単位を4種類(時間・日・月・年) から選べるようになりました。
- 取り込み時間により分割・時間単位の列により分割、いずれの分割方式においても、上記4種類の時間単位でのテーブル分割に対応しています。
テーブルを細かく分割することで、クエリ実行のパフォーマンス向上ならびにクエリ実行コストの削減が可能となります。
分割テーブルについて、詳しくは分割テーブルの概要を参照ください。
ワークフロー
Amazon Redshiftのクエリを利用したループ実行に対応🎉
- ワークフロー上のタスクのループ実行を、Amazon Redshiftのクエリ結果に基づいて行えるようになりました。
- ループ実行におけるカスタム変数の展開値を、Amazon Redshiftのクエリ結果に基づいて設定できます。
- カスタム変数の展開値が実行のたびに変動するようなワークフローを定義できるようになります。
なお、以下で簡単にループ実行の設定手順をご紹介します。
-
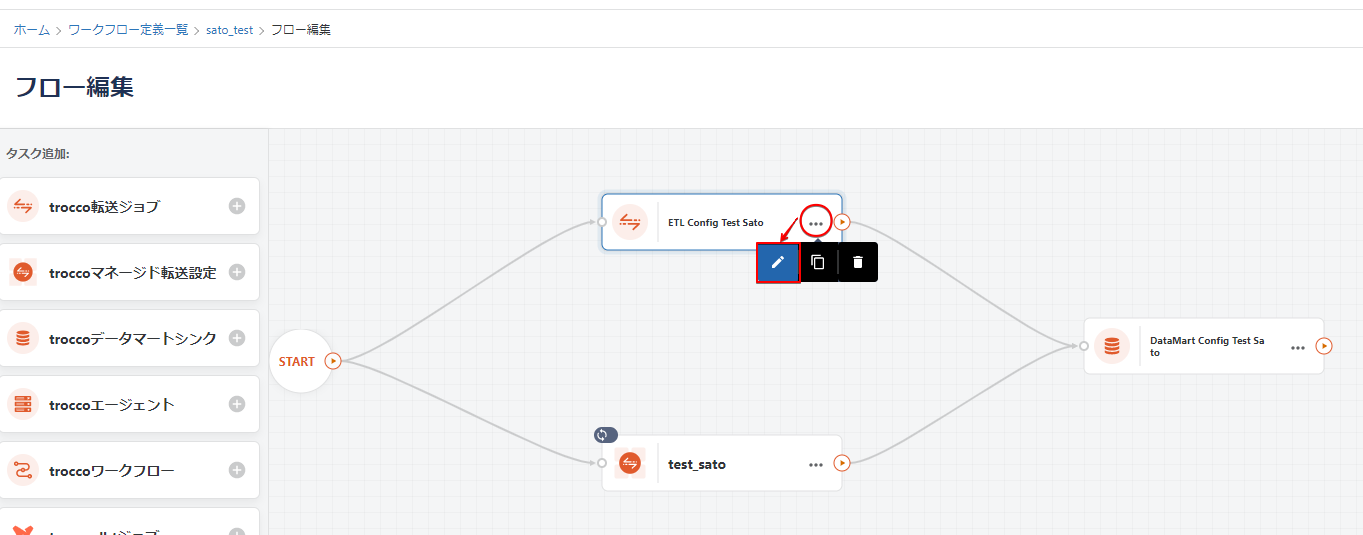
ワークフロー定義のフロー編集画面で、ループ実行したいタスク上のボタンを以下のようにクリックします。
-
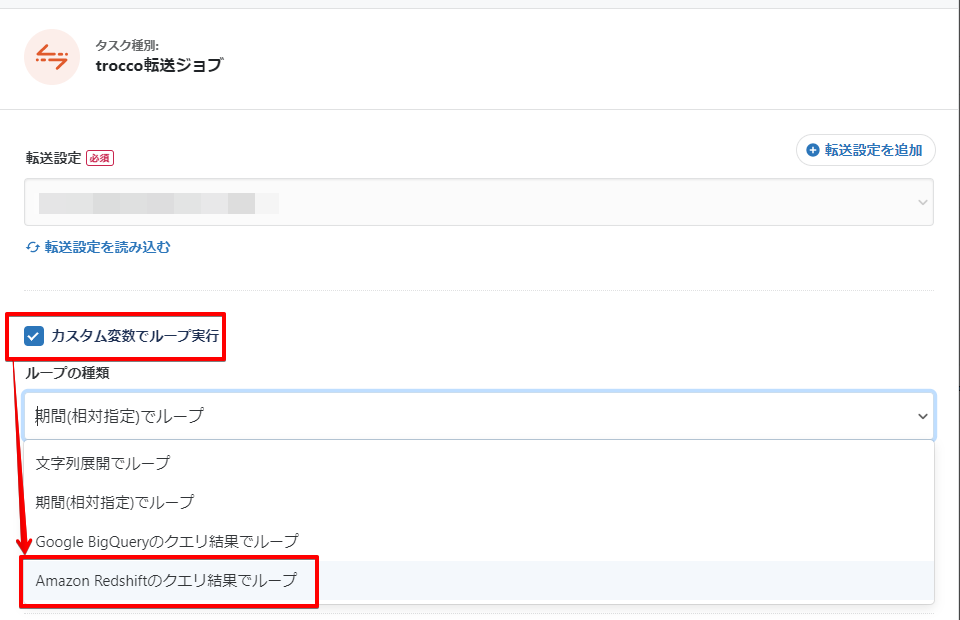
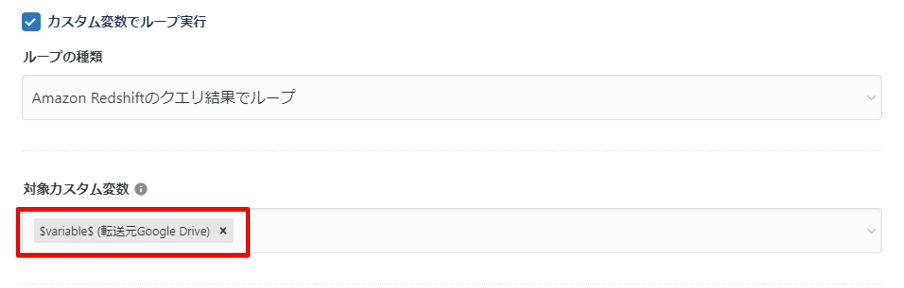
カスタム変数でループ実行を有効化し、ループの種類にてAmazon Redshiftのクエリ結果でループを選択します。
-
対象カスタム変数にて、任意のカスタム変数を指定します。
-
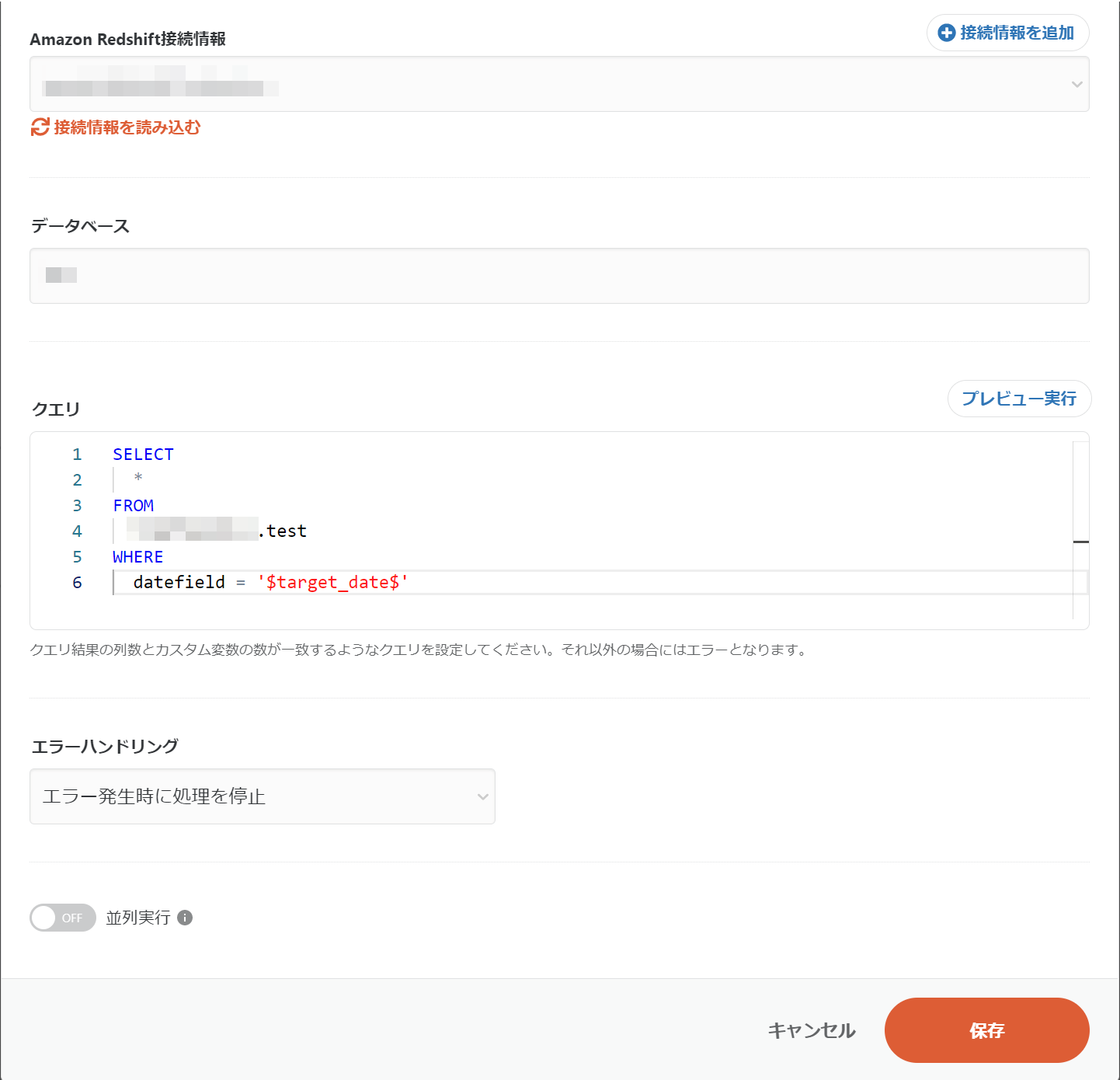
各種項目を入力し、保存をクリックします。
今回のリリース内容は以上です。
気になるリリースがございましたら、カスタマーサクセス担当者までお気軽にご連絡くださいませ。
Happy Data Engineering!