本ページでは、CDCデータ転送における転送先 - Google BigQueryについて説明します。
接続に関する設定については、Google BigQuery接続情報を参照ください。
事前準備
Google Cloud Projectの準備
事前にGoogle Cloud Projectを作成し、BigQuery APIを有効化する必要があります。
一時テーブルへの書き込みはBigQuery Storage Write API、マージ処理は通常のジョブとしての課金対象です。詳しくはBigQueryの料金 - Google Cloudを参照ください。
サービスアカウントの設定
CDCデータ転送では、サービスアカウント認証と個人のGoogleアカウント認証に対応しています。
サービスアカウントの発行手順については、Google BigQuery接続情報を参照ください。
必要な権限は以下のとおりです。
- BigQueryへのデータ読み書き権限
bigquery.datasets.createbigquery.datasets.getbigquery.jobs.createbigquery.tables.createbigquery.tables.deletebigquery.tables.exportbigquery.tables.getbigquery.tables.getDatabigquery.tables.listbigquery.tables.updatebigquery.tables.updateData
CDCデータ転送では、最大で50件のBigQueryクエリが同時に実行されます。
BigQuery側のデフォルト設定で許可されているクエリの同時実行数はプロジェクトあたり100件となっているため、他のアプリケーションやジョブが同じプロジェクトでクエリを実行している場合は、制限に達する可能性があります。
制限に到達した場合は、割り当ての表示と管理 - Google Cloudを参照し、割り当ての調整リクエストを検討してください。
設定項目
STEP1 詳細設定
| 項目 | 必須 | デフォルト値 | 内容 |
|---|---|---|---|
| 追加されたテーブル・カラムの追従設定 | No | カラムのみを自動追従(推奨) | 追加されたテーブル・カラムを転送先のテーブルに自動で追従するかを選択できます。詳しくは、CDCスキーマ自動追従を参照ください。 |
| バックフィル設定 | No | 有効(推奨) | テーブル・カラムの自動追従において、ジョブ実行時に追加や変更があったテーブルの全件転送を行うかどうかを設定します。詳しくは、CDCスキーマ自動追従を参照ください。 |
| テーブル連続失敗回数上限 | No | 20 | テーブルの同期が連続して失敗した際に、該当テーブルの同期を停止するまでの失敗回数を設定します。 停止した場合でも、他のテーブルの同期は継続されます。 値を空にすると上限なしとなり、エラーが発生しても同期を停止しません。詳しくは、同期対象のテーブル例外についてを参照ください。 |
STEP1 転送先設定
以下の設定項目については、転送先 - Google BigQueryの該当する項目を参照ください。
- Google BigQuery接続情報
- データセット
- データセットのロケーション
- データセットの自動作成オプション
| 項目 | 必須 | デフォルト値 | 内容 |
|---|---|---|---|
| 生ログデータセット | Yes | データセット名に「_raw_trocco_logs」のsuffixをつけた値 | CDCデータ転送の中間テーブルを保存するデータセットを指定します。 |
STEP2 スキーマ設定
| 項目 | 内容 |
|---|---|
| パーティション種別 | 転送先テーブルのパーティション種別を選択します。「日別」または「月別」を選択した場合は、パーティショニングの基準となるTimestamp型のカラムをあわせて選択します。 |
| カラム | 転送対象のカラム選択や、転送先でのカラム名・カラム型を設定します。転送先カラム型の設定については、転送先カラム型の設定を参照ください。 |
転送先カラム型の設定
転送先に出力する際のカラムの型を指定できます。スキーマ設定のカラム設定にて、対象カラムの転送先カラム型のドロップダウンから指定してください。
デフォルトでは、転送元のカラム型から自動マッピングされた型が選択されています。
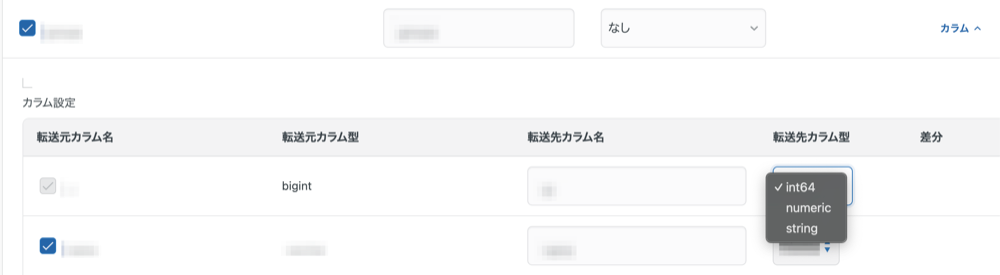
出力型を変更すると、差分列に型変更ありバッジが表示されます。出力型を元の自動マッピング値に戻すまで、バッジは継続して表示されます。

対応する型変換
選択可能な型は、転送元カラムの型ごとに以下のとおりです。BigQueryのデータ型表記で記載しています。
| 自動マッピングされる型 | 選択可能な出力型 |
|---|---|
datetime(ミリ秒・マイクロ秒・ナノ秒精度のtimestamp) |
datetime / timestamp / string datetimeはタイムゾーンを持たないため、timestampへ変更した場合はUTCとして扱われます。詳しくは、注意事項を参照ください。 |
timestamp(タイムゾーン付きtimestamp) |
timestamp / string |
date |
date / string |
time |
time / string |
int64(整数型) |
int64 / numeric / string |
float64(浮動小数点型) |
float64 / numeric / string※倍精度浮動小数点(double)からマッピングされた場合は float64 / string |
numeric |
numeric / string |
bool |
bool / string |
bytes |
bytes / string |
stringとjsonは、他の型への変更はできず固定です。
stringへの変換時の挙動
datetime/timestampをstringに変換した場合、エポック秒(整数)の文字列として書き込まれます。- 数値型を
stringに変換した場合は、元の値を保持したまま文字列として書き込まれます。
注意事項
- 出力型変更が利用できるのは、スキーマ設定タブで選択中のテーブルのみです。未選択テーブルでは出力型ドロップダウンが無効化されます。
- 出力型を変更してスキーマ設定を保存する場合、該当テーブルの全件転送(再読み込み)が必須です。スキーマ設定の保存時に確認モーダルが表示され、保存と同時に全件転送のジョブが作成されます。BigQuery側のテーブルは一度削除され、変更後の出力型で再作成されます。
- 転送元カラムの型がCDCで検知された場合は、従来どおり転送先テーブルの型は自動的に追従します。
- たとえば、転送元の
intカラムがstringに変更された場合、転送先テーブルもstring型のカラムで再作成され、スキーマ設定画面の出力型表示もstringに更新されます。
- たとえば、転送元の
datetime型はタイムゾーン情報を持たないため、timestamp型へ変換する際はUTCとしてキャストされます。転送元のデータベースが暗黙的にUTC以外のタイムゾーンを前提としてdatetime型のカラムを保持している場合、BigQuery側で意図しない時刻として扱われる可能性があります。- タイムゾーンの変更が必要な場合は、BigQuery側の後続処理でタイムゾーン変換を適用してください。
同期対象のテーブル例外について
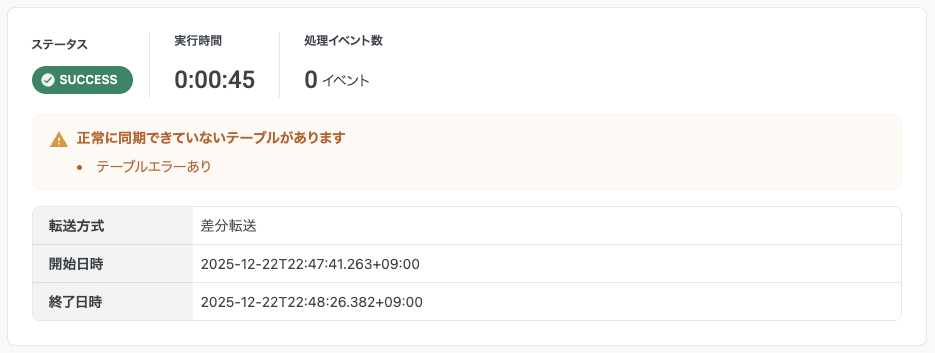
自動追従できない型変更など、転送ジョブ内の一部テーブルでエラーが発生した場合、エラーが発生したテーブルのみ例外として転送をスキップできます。
エラーが発生したテーブルが存在するジョブは、ジョブ自体は成功しますが「テーブルエラーあり」と表示されます。
失敗回数が連続失敗回数上限を超えた場合、テーブルの転送はスキップされます。
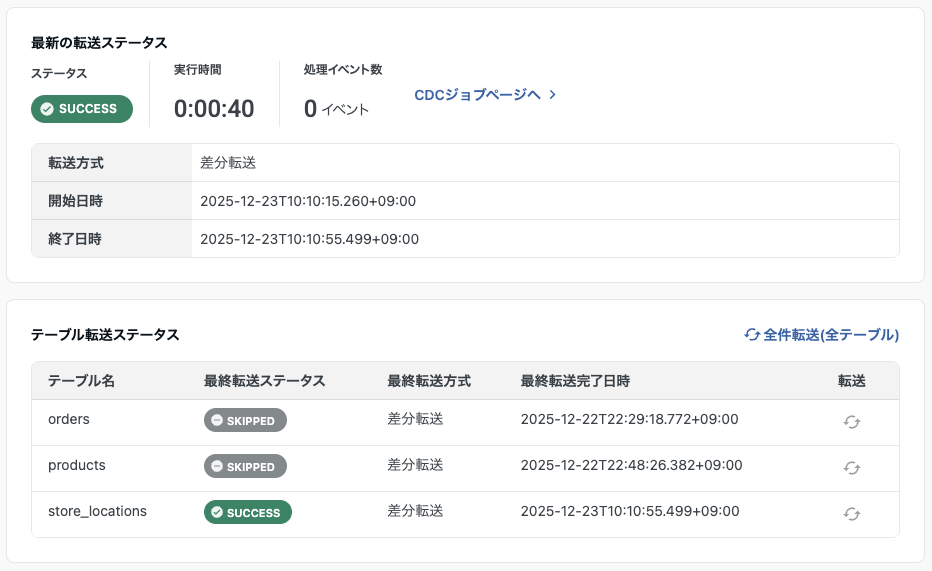
スキップされたテーブルへの対応
スキップされたテーブルを再度転送する場合は、「全件転送(選択テーブル)」または「全件転送(全テーブル)」を実行してください。
転送先のテーブルは一度削除され再作成されます。
差分転送に失敗するたびに読み込むログが徐々に増大するため、転送に失敗する回数が多くなると、遅延やエラーが発生する可能性があります。
テーブル連続失敗回数は原則設定することを推奨します。
転送元でエラーが発生した場合は、すべてのテーブルの転送がエラーとなり、ジョブ全体が失敗します。
制約事項
- 転送先テーブルは初回の全件転送時に再作成されます。既存のテーブルは利用できません。
- 9MBを超えるレコードは転送がスキップされます。