本機能を利用するには、以下の権限が必要です。
手動同期の場合
- メタデータ編集者ロール
自動同期機能を有効にする場合
以下のいずれかのロールに所属している必要があります。
- アカウント特権管理者ロール
- データストアアクセス管理者ロール
同期対象のデータストアに対し、アセット取得ユーザーのデータストア認証が必須です。
概要
COMETAで入力したメタデータをBigQuery・Snowflakeのアセットのメタデータとして反映できます。
- BigQuery: データセット・テーブル・カラムの説明
- Snowflake: スキーマ・テーブル・カラムのコメント
メタデータの自動同期機能を有効にすると、定期的に自動で同期させることが可能です。
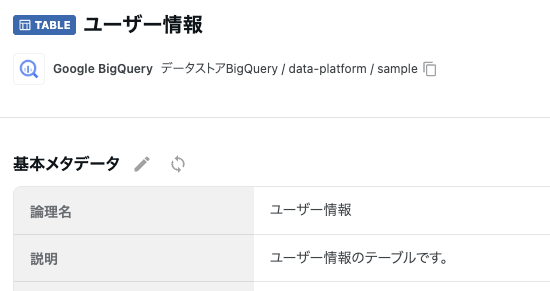
また、メタデータは基本メタデータ横の更新ボタンをクリックすることで、手動で同期させることもできます。
COMETAからの同期を実行すると、データストア側の既存のメタデータは常に上書きされます。
データストア側で直接編集した内容は、同期時に失われますのでご注意ください。
すでにデータストアのメタデータを整備済みの場合は、データストアのメタデータをCOMETAへインポートするのを推奨します。
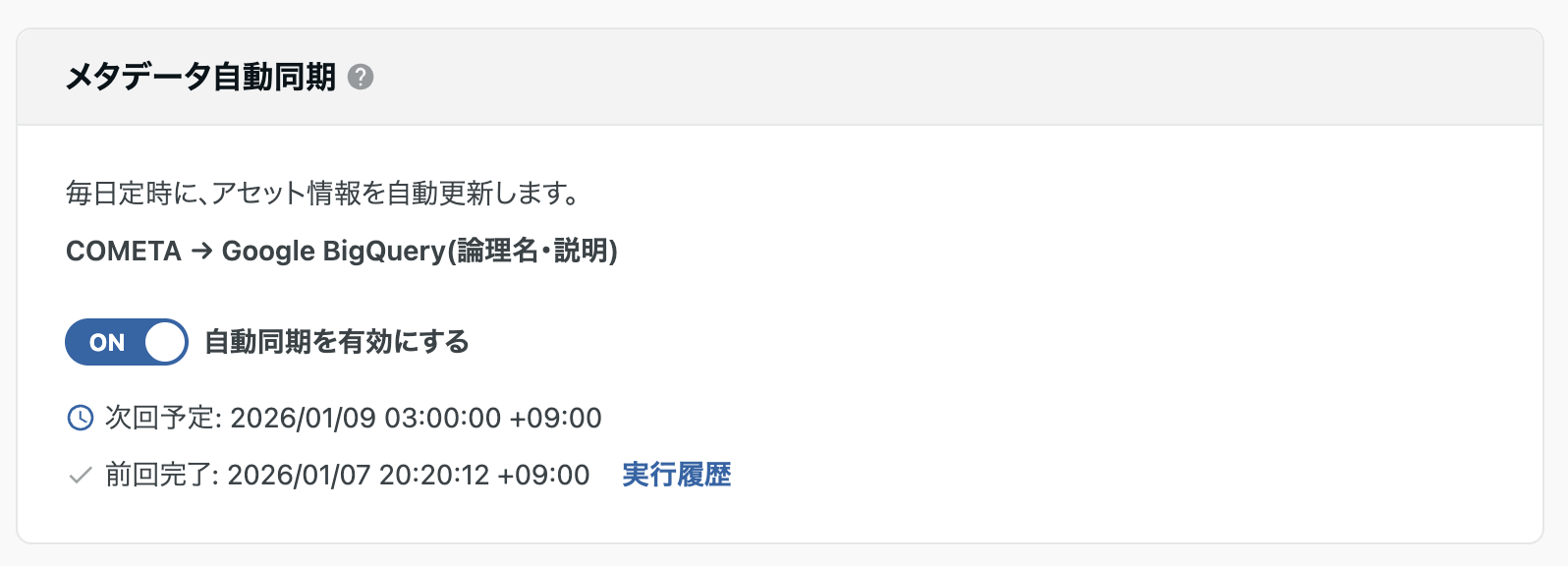
メタデータの自動同期
メタデータの自動同期機能は、データストア連携管理画面から有効にできます。
有効にすると、毎日定時にメタデータが自動更新されます。
自動同期では、前回の実行完了後に変更されたCOMETA側のメタデータとデータストア側のメタデータ(BigQueryの説明、Snowflakeのコメント)を比較して差分を検出し、COMETA側のメタデータをデータストア(BigQuery・Snowflake)に同期します。
初回有効化時は次回予定に同期予定日時が表示されます。
ジョブ実行後は、前回完了に実行完了日時が表示されます。
実行履歴リンクをクリックすると、詳細ログを確認できます。
直近90日のログを最大10件まで確認できます。
メタデータ自動同期の実行ログ
実行ログ画面では、以下の情報が表示されます。
| 項目 | 説明 |
|---|---|
| ステータス | 準備中、待機中、実行中、同期中、完了、またはエラー |
| 実行タイプ | スケジュール実行(定期実行)、再実行(手動)、またはCOMETAメンテナンス |
| 件数 | 同期に成功した件数と失敗した件数 |
| 開始日時 | ジョブの開始日時 |
| 終了日時 | ジョブの終了日時 |
最新のジョブが失敗している場合は、再実行できます。
同期フォーマット
COMETA上の各アセットの論理名と説明が利用されます。
「論理名: 説明」のフォーマットでデータセットのメタデータに同期されます。
例
テーブルの論理名が「ユーザー情報」、説明が「ユーザー情報のテーブルです。」の場合、「ユーザー情報: ユーザー情報のテーブルです。」の文字列がデータストアに同期されます。
論理名と説明がどちらも設定されていない場合、空の文字列でデータストア側のメタデータも上書きされます。
どちらかが設定されている場合は、設定されているメタデータの文字列のみが同期されます。
データストア側で必要なパーミッション
BigQueryの場合
BigQuery側のメタデータを更新するためには、アセット取得ユーザーに対し、以下のパーミッションを付与する必要があります。
bigquery.datasets.getbigquery.datasets.updatebigquery.tables.getbigquery.tables.update
または、個別のカスタムロール作成ではなく、BigQuery事前定義ロールを使用したい場合、BigQuery Data Ownerロールの使用が可能です。
Snowflakeの場合
Snowflake側のメタデータを更新するためには、アセット取得ユーザーに対し、以下のいずれかの方法でパーミッションを付与する必要があります。
以下のSQL例における<database_name>と<your_warehouse_name>と<schema_name>は、
ご利用のSnowflake環境に合わせて置き換えてください。
カスタムロールの作成(推奨)
セキュリティの観点から、必要最小限の権限を持つ
カスタムロールの作成を推奨します。
カスタムロール作成例:
-- ステップ 1: ロールの作成 (USERADMIN または SECURITYADMIN ロールが必要)
-- 権限管理専用のロールに切り替えて、新しいロールを作成します。
USE ROLE USERADMIN;
CREATE ROLE IF NOT EXISTS cometa_metadata_sync;
-- ステップ 2: ロールの階層構造の設定 (Snowflakeの推奨ベストプラクティス)
-- この新しいロールを SYSADMIN に継承させます。
-- これにより、SYSADMIN はこのロールが持つ権限を管理でき、
-- 作成されたオブジェクトも操作可能になります。
GRANT ROLE cometa_metadata_sync TO ROLE SYSADMIN;
-- ステップ 3: ウェアハウスの使用権限付与
-- クエリを実行したりメタデータを取得したりするには、
-- 計算リソース(ウェアハウス)が必要です。
USE ROLE SECURITYADMIN;
GRANT USAGE ON WAREHOUSE <your_warehouse_name> TO ROLE cometa_metadata_sync;
-- ステップ 4: データベースおよびスキーマレベルのアクセス権限付与
-- データベースとスキーマに「入る」ための権限(USAGE)を与えます。
GRANT USAGE ON DATABASE <database_name> TO ROLE cometa_metadata_sync;
GRANT USAGE ON SCHEMA <database_name>.<schema_name> TO ROLE cometa_metadata_sync;
-- ステップ 5: メタデータ管理のための「所有権 (OWNERSHIP)」の譲渡
-- Snowflakeでは、メタデータの変更(COMMENT ON や ALTER)を行うには、
-- そのオブジェクトの所有者である必要があります。
-- 「COPY CURRENT GRANTS」を付けることで、既存の共有設定を
-- 維持したまま所有権を移せます。
GRANT OWNERSHIP ON SCHEMA <database_name>.<schema_name>
TO ROLE cometa_metadata_sync COPY CURRENT GRANTS;
GRANT OWNERSHIP ON ALL TABLES IN SCHEMA <database_name>.<schema_name>
TO ROLE cometa_metadata_sync COPY CURRENT GRANTS;
GRANT OWNERSHIP ON ALL VIEWS IN SCHEMA <database_name>.<schema_name>
TO ROLE cometa_metadata_sync COPY CURRENT GRANTS;
GRANT OWNERSHIP ON ALL MATERIALIZED VIEWS IN SCHEMA <database_name>.<schema_name>
TO ROLE cometa_metadata_sync COPY CURRENT GRANTS;
-- ステップ 6: 将来作成されるオブジェクトへの権限設定 (Future Grants)
-- 今後このスキーマ内に新しく作成されるテーブルやビューに対しても、
-- 自動的にこのロールが所有者になるように設定します。
-- これを行わないと、新しいテーブルを作るたびに
-- 再設定が必要になります。
GRANT OWNERSHIP ON FUTURE SCHEMAS IN DATABASE <database_name> TO ROLE cometa_metadata_sync;
GRANT OWNERSHIP ON FUTURE TABLES IN SCHEMA <database_name>.<schema_name> TO ROLE cometa_metadata_sync;
GRANT OWNERSHIP ON FUTURE VIEWS IN SCHEMA <database_name>.<schema_name> TO ROLE cometa_metadata_sync;
GRANT OWNERSHIP ON FUTURE MATERIALIZED VIEWS IN SCHEMA <database_name>.<schema_name> TO ROLE cometa_metadata_sync;
SYSADMIN ロールの利用
最も簡単な方法として、アセット取得ユーザーに
SYSADMIN ロールを付与する方法があります。
GRANT ROLE SYSADMIN TO USER <user_name>;
注意事項
- データストアに同期した説明がCOMETAのデータストアに関するメタデータに反映されるのは、日次のデータストア連携ジョブの実行後です。
- 同期したメタデータがCOMETA上に反映されるまで、最大24時間程度かかる可能性があります。
- ビューおよびマテリアライズドビューでは、カラムの説明は同期されません。テーブルの説明は同期されます。
- (BigQueryのみ)COMETAの基本メタデータの説明の最大長は、BigQueryの説明の最大長よりも大きいため、以下のBigQueryの制限を超えた文字列は切り詰められます。
- データセットの説明: 最大16,384文字
- テーブルの説明: 最大16,384文字
- カラムの説明: 最大1,024文字
TIPS: データストアのメタデータをCOMETAにインポートする
BigQueryやSnowflakeに保存済みのメタデータをCOMETAの基本メタデータの説明としてインポートできます。
以下のSQLを実行し、実行結果をCSV形式でダウンロードすると、メタデータインポート機能でインポート可能なCSV形式で取得できます。
BigQueryの場合
以下のSQLのproject.dataset.INFORMATION_SCHEMA部分は、対象のプロジェクトIDとデータセットIDに置き換えてください。
データセットの説明をインポートする
SELECT
s.catalog_name AS project_id,
s.schema_name AS dataset_id,
TRIM(s.option_value, '"') AS description
FROM
`project.INFORMATION_SCHEMA.SCHEMATA_OPTIONS` s
WHERE
s.option_name = 'description'
ORDER BY
project_id,
dataset_id;
テーブルの説明をインポートする
SELECT
t.table_catalog AS project_id,
t.table_schema AS dataset_id,
t.table_name AS table_id,
TRIM(t.option_value, '"') AS description
FROM
`project.dataset.INFORMATION_SCHEMA.TABLE_OPTIONS` t
WHERE
t.option_name = 'description'
ORDER BY
project_id,
dataset_id,
table_id;
カラムの説明をインポートする
SELECT
c.table_catalog AS project_id,
c.table_schema AS dataset_id,
c.table_name AS table_id,
c.column_name AS column_id,
c.description AS description
FROM
`project.dataset.INFORMATION_SCHEMA.COLUMN_FIELD_PATHS` c
WHERE
c.description IS NOT NULL
ORDER BY
project_id,
dataset_id,
table_id,
column_id;
Snowflakeの場合
スキーマのコメントをインポートする
SELECT
CATALOG_NAME AS "database_name",
SCHEMA_NAME AS "schema_name",
COMMENT AS "description"
FROM
<database_name>.INFORMATION_SCHEMA.SCHEMATA
WHERE
COMMENT IS NOT NULL
AND SCHEMA_NAME NOT IN ('INFORMATION_SCHEMA')
ORDER BY
"database_name",
"schema_name";
テーブルのコメントをインポートする
SELECT
TABLE_CATALOG AS "database_name",
TABLE_SCHEMA AS "schema_name",
TABLE_NAME AS "table_name",
COMMENT AS "description"
FROM
<database_name>.INFORMATION_SCHEMA.TABLES
WHERE
COMMENT IS NOT NULL
AND TABLE_SCHEMA NOT IN ('INFORMATION_SCHEMA')
ORDER BY
"database_name",
"schema_name",
"table_name";
カラムのコメントをインポートする
SELECT
TABLE_CATALOG AS "database_name",
TABLE_SCHEMA AS "schema_name",
TABLE_NAME AS "table_name",
COLUMN_NAME AS "column_name",
COMMENT AS "description"
FROM
<database_name>.INFORMATION_SCHEMA.COLUMNS
WHERE
COMMENT IS NOT NULL
AND TABLE_SCHEMA NOT IN ('INFORMATION_SCHEMA')
ORDER BY
"database_name",
"schema_name",
"table_name",
ORDINAL_POSITION;